Kubelet Restarts in Kubernetes 1.35.1: Test It Like a P1
I’ve watched a “safe” kubelet restart knock 20% of backends out of a load balancer for 40 seconds.
If your last outage included Pods flipping NotReady during node maintenance, treat Kubernetes 1.35.1 as a time-boxed drill, not a casual patch you “get to” later.
Dates matter more than opinions
Jan 13, 2026 comes fast.
The Kubernetes patch train uses a cherry-pick deadline (Jan 9, 2026) and a target release date (Jan 13, 2026). That means the patch contents stop changing days before you see the bits. Plan as if your favorite fix will miss the train, because it often does.
- What I do in practice: I schedule a 60 minute staging canary window before the cherry-pick deadline, not after. That way, if we find a real regression, we still have time to pick a mitigation that does not involve panic.
- What I do not do: I do not assume “it’s a patch” means “it’s harmless.” Patch releases break things in boring ways, which makes them harder to spot.
The kubelet restart failure mode you actually feel
This bit me when we restarted kubelet during a kernel rollout.
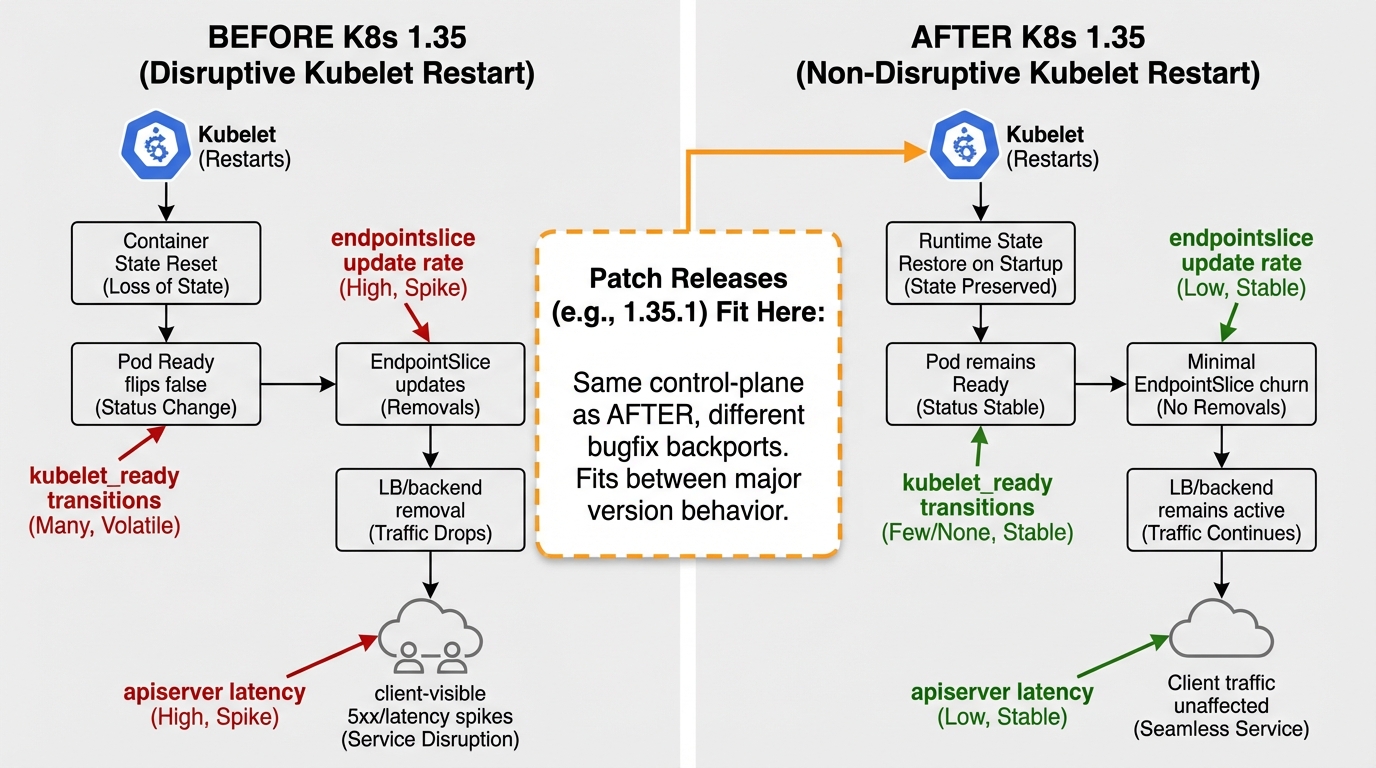
Nothing “crashed,” but Pods flipped NotReady, EndpointSlices churned, and the external load balancer started failing health checks. Users saw 502s. The graphs looked like a saw blade for about a minute.
Kubernetes 1.35 introduced work to reduce readiness chaos during kubelet restarts (KEP-4781). You should not trust it blindly. You should prove it on your stack: your CNI, your ingress, your PDBs, your readiness probes, your autoscalers, and whatever glue you built at 2 AM six months ago.
Before testing, get a baseline of your pod health and restart counts across the cluster:
# Check pod status across all namespaces
kubectl get pods -A -o wide --sort-by='.status.startTime'
# Show pods with non-zero restart counts (potential instability indicators)
kubectl get pods -A -o custom-columns=\
NAMESPACE:.metadata.namespace,\
NAME:.metadata.name,\
RESTARTS:.status.containerStatuses[0].restartCount,\
STATUS:.status.phase,\
NODE:.spec.nodeName \
| awk 'NR==1 || $3 > 0'
# Get a quick health summary: how many pods per state
kubectl get pods -A --no-headers | awk '{print $4}' | sort | uniq -c | sort -rnA reproducible canary test (restart loop)
Do this once.
Pick one canary node that actually serves traffic. Keep load on it. Then restart kubelet repeatedly, because the “one restart on an empty node” test tells you almost nothing.
- Baseline snapshot: Record request error rate at the edge, apiserver latency, Pod readiness transitions, and EndpointSlice update rate for 5 minutes before you touch anything.
- Restart loop: Run sudo systemctl restart kubelet 10 times with a 30 second pause between restarts. Watch whether Pods go NotReady without container restarts, and whether EndpointSlice updates spike.
- Pass or fail: Decide this up front. For most teams, “no user-visible error spike” beats any internal metric. For critical systems, I require a written go/no-go, because “looked fine” turns into a postmortem sentence.
Monitor kubelet logs during and after the restart loop to catch issues early:
# Watch kubelet logs in real-time during the restart test
journalctl -u kubelet -f --no-pager | grep -i "error\|warn\|fail\|notready"
# After the test, check for specific restart-related issues
journalctl -u kubelet --since "1 hour ago" --no-pager | \
grep -c "node status update\|PLEG\|syncLoop"
# Check if any pods changed state during the kubelet restart
kubectl get events -A --sort-by='.lastTimestamp' | \
grep -i "notready\|unhealthy\|killing\|backoff" | tail -20
# Verify node condition after restart loop
kubectl describe node $(hostname) | grep -A5 "Conditions:"Do the meaner test (node reboot under load)
Reboot it.
Kubelet restart behavior matters, but node reboots still trigger a different chain of events. Reboot the canary node during steady traffic and watch how quickly your load balancer puts the node back in rotation. If you only test kubelet, you miss the ugly interactions with CNI startup ordering and readiness probes.
Some folks skip canaries for patch releases. I don’t. I get it if you run dev clusters, but production deserves paranoia.
Identity changes: Pod certificates can step on your existing machinery
The thing nobody mentions is the quiet double-rotation.
If you run a service mesh plus custom certificate tooling, you can end up with two controllers trying to “help” the same Pod. Kubernetes 1.35 includes Pod certificates via PodCertificateRequest (KEP-4317) in beta. Even if you never enable it, test your current flows next to it, because overlaps show up as permission errors, unexpected mounts, or cert files that change twice as fast as your clients expect.
- What to watch: Cert issuance failures, rotation spam, and silent fallbacks where the mesh “works” but uses an older cert than you think.
- Quick mitigation: If you see doubled rotation, disable one system in staging and retest. Do not “ship and see” on a Monday.
Runtime reality: containerd v1.x will not stay comfortable
Stop punting this.
Kubernetes 1.35 marks a shift away from containerd v1.x support. If you combine a Kubernetes upgrade, a runtime major upgrade, and your vendor’s packaging quirks in the same week, you will write a long postmortem. I don’t trust “we’ll do it later” as a strategy.
Check what you run on every node before you touch 1.35.1. Then file the runtime migration ticket you have avoided. Other stuff in this release: dependency bumps, some image updates, the usual.
Monitoring kubelet restarts with Prometheus
If you run Prometheus (or any compatible metrics backend), set up alerts that catch kubelet restart impact before users notice:
# PromQL: Count of pod restarts per node in the last 15 minutes
# Use this to detect instability after kubelet restarts
sum by (node) (
increase(kube_pod_container_status_restarts_total[15m])
) > 5
# PromQL: Detect nodes flipping between Ready and NotReady
# Alert when a node changes readiness state more than twice in 10 minutes
changes(kube_node_status_condition{condition="Ready",status="true"}[10m]) > 2
# PromQL: EndpointSlice churn rate (signals load balancer instability)
rate(endpointslice_controller_changes_total[5m]) > 10
# PromQL: kubelet restart count (systemd-level)
# Requires node-exporter with systemd collector
increase(node_systemd_unit_state{name="kubelet.service",state="activating"}[30m]) > 1Copy-paste workflow (generic)
Keep it boring.
This stays upstream-generic on purpose. Your distro may wrap these steps, and managed providers will do their own thing, so adapt it.
- Verify versions: Run kubectl version –short and kubelet –version and write the output into the change record.
- Stage upgrade (kubeadm): Run kubeadm upgrade plan, then kubeadm upgrade apply v1.35.1 in staging first.
- Canary kubelet restart: Restart kubelet on one traffic-serving node. Then do the restart loop and the reboot test.
Track Kubernetes release timelines and support windows on the Kubernetes Release History page. Use the K8s Deprecation Checker to scan your manifests for deprecated APIs before upgrading.
Red flags I grep for while testing
These show up fast.
I watch events, logs, and client errors in the same window. If you only watch Pods, you miss the customer impact.
- NotReady flaps tied to kubelet restarts: Especially when containers never restarted, because that points at readiness state handling and downstream endpoint churn.
- EndpointSlice spikes and controller retries: Traffic can drop while every Pod looks “Running.” That’s the worst kind of incident.
- CRI warnings about deprecation or losing support: Treat them as a migration ticket, not “log noise.”
- Cert issuance or rotation errors: If you run workload identity tooling, assume a subtle overlap until proven otherwise.
Test it like you mean it.
If staging teaches you something uncomfortable, good. There’s probably a cleaner way to automate all of this, but the manual drill still catches the sharp edges.
Official References
- Kubernetes Kubelet Reference Documentation — flags, configuration, and behavior
- Kubernetes Cluster Troubleshooting Guide — official debugging workflows for nodes and pods
- Kubernetes 1.35 Changelog — upstream changelog with full PR list
Keep Reading
- Kubernetes Release History
- K8s Deprecation Checker — scan manifests for deprecated APIs before upgrading
- Kubernetes Upgrade Checklist: the runbook for minor version upgrades
- Kubernetes EOL policy explained for on-call humans
- Kubernetes 1.35 release: the stuff that can break your cluster
Related Reading
- Kubernetes Upgrade Checklist — The runbook for safe minor version upgrades
- Kubernetes EOL Policy Explained — Know when your version loses support
- Debugging Kubernetes Nodes in NotReady State — Troubleshoot the most common upgrade symptom
- Kubernetes 1.35: What Can Break Your Cluster — The current release’s breaking changes
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.
Track These Releases