PostgreSQL vs MongoDB for JSON Workloads in 2026: What Breaks First
I’ve watched “JSON everywhere” projects turn into slow queries, angry on-call shifts, and surprise storage bills.
PostgreSQL JSONB and MongoDB both run JSON-heavy APIs fine, right up until your indexing, update patterns, or ops habits hit their sharp edges. This guide gives you a decision framework, benchmark shapes worth testing, and a migration path that does not wreck your weekends.
The decision framework I actually use
Here’s the thing.
Most teams pick a database based on what feels easy on day 7, then spend month 7 paying interest. I bias toward PostgreSQL when the workload needs reliable querying and reporting, and I bias toward MongoDB when the workload stays document-centric and the org can enforce schema discipline in code.
- Pick PostgreSQL JSONB when your API mixes JSON with real relational needs: joins across entities, aggregates, “show me revenue by plan,” and constraints that must never lie.
- Pick MongoDB when your critical path stays document-shaped: fetch-by-id, patch a nested field, filter on a small set of indexed keys, and move on.
- If you already smell ETL duct tape: choose Postgres, or plan a hybrid early. I do not trust “we’ll just export to a warehouse later” as a strategy.
Some folks run Mongo for everything because “it’s JSON.”
I get the appeal, but it usually backfires when product asks for cross-tenant reporting, fraud rules, or anything that needs joins. You can build those on Mongo, you just end up rebuilding a reporting system next to it.
Benchmark the queries you will run, not the ones that look good in a blog post
Benchmarks that only test “insert 1M docs” waste your time.
JSON APIs usually hammer a small set of query shapes: containment checks, nested field filters, array membership, tenant-scoped listings with pagination, and small patch updates under concurrency.
- Containment and membership: “does this object contain this key and value?”
- Nested scalar filters: “profile.limits.seats >= 10” plus sort by created_at.
- Array membership: “tags contains billing,” until tags turns into a junk drawer.
I like a simple harness: one dataset, the same query shapes, pinned versions, and explain plans saved to disk.
Measure P50 and P95 under steady concurrency, then watch what happens when maintenance kicks in. Autovacuum can spike tail latency on Postgres, and checkpoint or compaction work can do the same on Mongo. You want to see those spikes in a test, not during an incident.
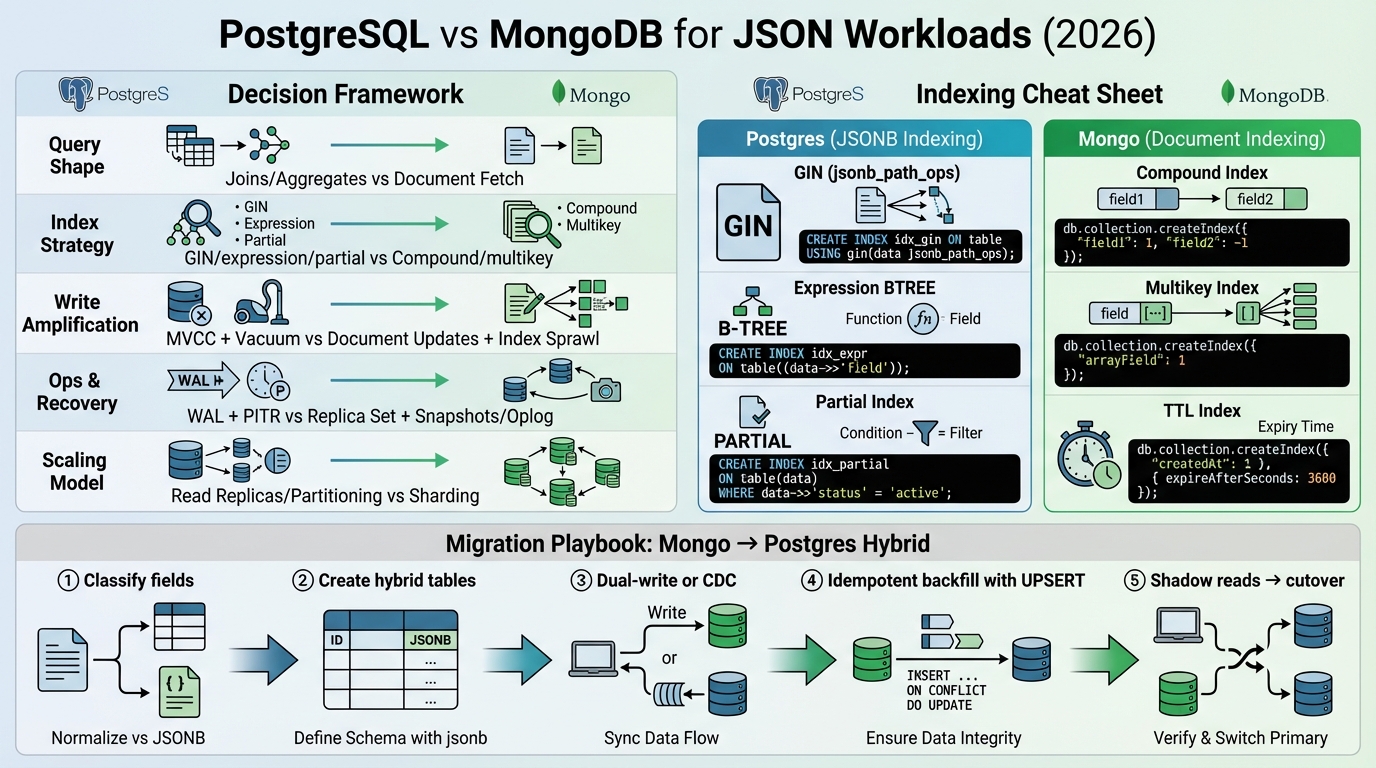
Indexing: Postgres rewards precision, Mongo rewards restraint
Indexing causes most of the pain.
Mongo feels easy early, Postgres feels fiddly early. Then you hit scale and the roles flip.
Postgres JSONB: use GIN for containment, btree for hot paths
The mistake I see most: teams treat a full-document GIN index like a magic spell.
That index can help containment queries, but it grows fast and it adds write cost. I start by indexing tenant scope and time ordering, then I add 1 to 3 expression indexes for the exact JSON paths that show up in slow queries.
- Use a GIN index when you truly run containment queries: if you use @> across lots of keys, a GIN index can pay off. Prefer jsonb_path_ops when your workload mostly uses @> containment, and confirm in the PostgreSQL docs for your version.
- Use expression btree indexes for repeated JSON path filters: if you filter on doc->>’field’ or a nested path, index that exact expression. Standardize the query syntax, or the planner will not match the index consistently.
- Use partial indexes for stable predicates: multi-tenant systems often benefit from indexing only “active” rows, but your query must include the predicate.
One detail that bit me: the Postgres path operators are #> and #>>, not “#->”.
If your codebase mixes operators and casts, you will create indexes that look right and never get used. I’ve seen that exact bug waste days because the queries “looked indexed” in code review.
MongoDB: compound indexes work, index sprawl kills you
Mongo indexing stays readable, which is a genuine advantage.
The trap is social, not technical. Teams add one index per endpoint, then write throughput drops and the working set stops fitting in memory.
- Get compound index order right: align filters and sorts with index prefix rules, or you’ll scan more than you think.
- Watch multikey indexes on arrays: large or unbounded arrays can explode index entries and memory pressure.
- Do not assume covered queries save you: most APIs return full documents, so you still hit storage.
Write amplification: JSON updates hurt in different ways
Reads get the headlines, writes pay the bill.
Most JSON APIs do “read, patch, list” all day. The update model matters more than your teammates want to admit.
Postgres: MVCC rewrites rows, VACUUM cleans up later
Postgres updates create new row versions.
On big JSONB documents, frequent updates mean more WAL, more dead tuples, and more bloat if autovacuum lags. The fix stays boring and effective: promote hot fields into columns, and keep JSONB for optional attributes and cold blobs.
- Promote churny fields: status, counters, updated_at, state-machine fields.
- Keep JSONB for the long tail: tenant-specific attributes that rarely drive filters.
Mongo: patching feels great until documents keep growing
Mongo makes patch updates easy.
$set and $inc fit JSON-heavy APIs nicely, but documents that grow without bounds (event logs, append-only histories) will hurt. Split unbounded events into a separate collection or table. Yes, even if it feels less “document-y.”
Ops reality: backups, PITR, replication, and Kubernetes
If you cannot restore, you do not have a database.
I don’t care how fast your P95 looks if your restore plan stops at “nightly dump.” Test a restore, time it, and write the runbook like you mean it.
- Postgres PITR works well when you run it properly: base backups plus WAL archiving, restore to a timestamp or LSN. It takes work, but it behaves predictably once you automate it.
- Mongo PITR depends on topology and tooling: managed services often give you point-in-time restore, self-managed setups often drift into “we copy files and hope.” Budget time to get this right early.
- Kubernetes adds failure modes: treat databases like stateful systems, not another Deployment. Use StatefulSets, real disruption budgets, and backups that run outside the node that just died.
Opinion: If you can’t test your restore path quarterly, you shouldn’t run your database in-cluster.
Migration playbook: Mongo to Postgres JSONB plus relational columns
The clean migration almost never means “one table, one jsonb column.”
The hybrid model wins because it lets you index and constrain the fields that matter, while still storing tenant-specific long-tail attributes without endless migrations.
- Step 1, classify fields: promote ids, tenant_id, created_at, status, plan, seats. Keep optional attributes in JSONB.
- Step 2, design for query shapes: index tenant-scoped listings and the 1 to 3 JSON paths that drive filters.
- Step 3, pick dual-write or CDC: dual-write stays simpler but you must handle ordering and retries, CDC reduces app changes but adds moving parts.
- Step 4, reconcile like a pessimist: compare counts and checksums per tenant and time bucket. Do not trust “it seems fine.”
Backfills fail.
Make them idempotent, restartable, and boring. Then do shadow reads per endpoint, compare responses, and keep a kill switch per tenant for the read path until you trust it.
Anti-patterns that keep showing up
I’ll keep this blunt.
These patterns look convenient, then they eat your latency budget or your ops time.
- Postgres: everything in JSONB: you lose constraints, you force broad indexes, and you end up rebuilding relational modeling badly.
- Postgres: heavy updates on giant JSONB plus a big GIN index: you pay write amplification twice. Promote hot fields.
- Mongo: unbounded arrays in documents: event logs do not belong inside one record.
- Mongo: index-per-endpoint: write throughput drops, RAM requirements climb, and nobody wants to delete an index later.
- Both: “we have backups” without a restore drill: you have a story, not a recovery plan.
Bottom line
If your JSON workload needs joins, constraints, and reporting, pick Postgres and model hot fields as columns.
If your workload stays document fetch plus bounded patch updates, pick Mongo and keep your indexes and schema discipline tight. Other stuff in this release of your architecture decision: managed-service pricing, staff skill, compliance checklists, the usual. There’s probably a better way to test all of this, but this framework catches the failures I see most often.
Sharding and horizontal scaling: when vertical stops working
Vertical scaling buys time. Horizontal scaling buys survival. Both databases offer it, but the experience is nothing alike.
MongoDB: built-in sharding, genuine simplicity
MongoDB shipped sharding from the start, and it shows. You pick a shard key, enable sharding on the collection, and the balancer distributes chunks across shards. The driver-level routing means your application code barely changes.
The catch: shard key selection is permanent and it defines your entire scaling story. A bad shard key (low cardinality, monotonically increasing) creates hot shards that defeat the purpose. I have seen teams reshard by dumping and reloading entire collections because they picked created_at as a shard key and all writes landed on one node.
- Good shard keys: tenant_id for multi-tenant SaaS, hashed _id for write-heavy analytics, compound keys that match your primary query pattern.
- Avoid: timestamps alone, boolean fields, anything with fewer than a few thousand distinct values.
- Resharding: MongoDB 5.0+ added live resharding, but it is resource-intensive and you should test it under realistic load before depending on it in production.
PostgreSQL: sharding exists, but it is not free
Native PostgreSQL does not shard. You get table partitioning (declarative since PG 10), which splits data within a single instance. For actual distributed sharding, you need an extension.
- Citus (now part of Microsoft): the most mature option. Distributes tables across worker nodes, supports distributed queries, and handles tenant isolation well. If your workload is multi-tenant, Citus fits naturally because you shard by tenant_id and most queries stay single-shard.
- Native partitioning: good for time-series data, archival, and partition pruning in queries. Not horizontal scaling, but it keeps individual partition sizes manageable and enables fast DROP PARTITION instead of slow DELETEs.
- Foreign Data Wrappers (FDW): technically federate queries across servers, but performance and transaction semantics make this a last resort, not a strategy.
Bottom line on scaling: if you know you need transparent horizontal sharding from day one, MongoDB is genuinely easier. If your scaling needs are tenant-based and you want relational guarantees, Citus on Postgres is the pragmatic choice. If you just need time-based data management, native partitioning handles it without external tooling.
Cost at scale: the bill nobody plans for
Both databases are free to run. Neither is free to operate at scale. The cost structures diverge in ways that surprise teams around the 1TB mark.
Licensing and managed service pricing
- PostgreSQL: fully open source, no enterprise tier, no license fees ever. Managed services (RDS, Cloud SQL, AlloyDB, Supabase) charge for compute and storage. RDS PostgreSQL typically costs 10-30% less than equivalent MongoDB Atlas at the same tier.
- MongoDB: Community Edition is free (SSPL license since 2018, which some orgs reject). MongoDB Atlas is the managed service and the pricing scales with storage, IOPS, and backup retention. Atlas charges for data transfer between regions, which adds up fast in multi-region setups.
Operational costs that hide until month 6
- Storage efficiency: PostgreSQL JSONB compresses and deduplicates better than BSON in most workloads I have measured. A 500GB MongoDB dataset often lands at 350-400GB in PostgreSQL JSONB with the same data, because BSON stores field names per document.
- Memory requirements: MongoDB wants your working set in RAM. When it does not fit, performance falls off a cliff. PostgreSQL is more graceful under memory pressure thanks to its buffer pool and OS page cache cooperation, but it still benefits from generous shared_buffers.
- Backup costs: MongoDB Atlas continuous backup is included in higher tiers but adds cost on lower ones. PostgreSQL PITR with WAL archiving to S3 costs almost nothing for storage, but you need to build the automation yourself (or use pgBackRest, which you should anyway).
- Team cost: good PostgreSQL DBAs are expensive and scarce. Good MongoDB ops engineers are equally scarce but often less specialized because MongoDB abstracts more away. Factor in hiring difficulty if you are choosing for a team of 3-5 engineers.
Migration paths: moving between the two without losing data or sleep
Migrations between PostgreSQL and MongoDB happen more often than either community admits. The typical direction is Mongo to Postgres, but Postgres to Mongo happens when teams need a document-first model for a new service.
MongoDB to PostgreSQL
- pgloader: the standard ETL tool for loading into Postgres. Handles type mapping, batching, and resumability. You will still need to write custom mapping for nested documents into your target schema (promoted columns plus JSONB remainder).
- Custom dual-write pipeline: write to both databases during a transition window, reconcile per-entity counts and checksums, then cut reads over per-endpoint. This is the safest approach for production services that cannot afford downtime.
- mongodump + transform + COPY: for one-time migrations of datasets under 100GB, dump to JSON, transform with a script, and COPY into Postgres. Fast, simple, no ongoing sync.
PostgreSQL to MongoDB
- mongoexport/mongoimport: for simple table-to-collection moves. Export Postgres rows as JSON, import into Mongo. Works for flat structures, fails for anything with joins or foreign keys.
- Change Data Capture (CDC): use Debezium on PostgreSQL WAL to stream changes into MongoDB via Kafka. This is the enterprise-grade approach for ongoing sync during a migration window. Complex to set up, reliable once running.
- Denormalize first: before migrating, create materialized views in Postgres that match your target document shape. Migrate the denormalized views, not the normalized tables. This prevents the “we moved the data but the queries are wrong” problem.
Whichever direction you go: reconcile obsessively, keep a rollback path for at least 2 weeks, and do not declare the migration done until you have run a full read comparison under production traffic patterns.
Frequently Asked Questions
- Is PostgreSQL good for JSON data? Yes. PostgreSQL’s JSONB type provides efficient binary storage, GIN indexing, and rich query operators for JSON data. For many JSON workloads, PostgreSQL performs comparably to MongoDB while giving you the benefits of a relational database including ACID transactions and SQL queries.
- When should I choose MongoDB over PostgreSQL? Choose MongoDB when your data is highly variable with no consistent schema, when you need horizontal sharding across multiple servers, or when your team has more experience with document databases. MongoDB excels at rapid prototyping and workloads with deeply nested, polymorphic documents.
- Can PostgreSQL replace MongoDB? For many use cases, yes. PostgreSQL’s JSONB support covers most document database needs while providing stronger consistency guarantees. However, MongoDB has advantages in native sharding, flexible schema evolution without migrations, and purpose-built document query patterns.
- Which is faster for JSON queries: PostgreSQL or MongoDB? It depends on the query pattern. PostgreSQL with proper JSONB indexing often matches or exceeds MongoDB for read-heavy workloads on a single node. MongoDB tends to perform better for deeply nested document traversals and write-heavy workloads at scale with sharding.
- What breaks first when scaling PostgreSQL vs MongoDB with JSON? PostgreSQL typically hits scaling limits on write throughput first, since vertical scaling has limits and native sharding is less mature than MongoDB’s. MongoDB’s eventual consistency model can cause issues with data integrity at scale. Both require careful architecture decisions as data grows beyond a single node.
Side-by-side: JSON queries in PostgreSQL vs MongoDB
Theory is useful. Seeing the actual query syntax side-by-side is better. These examples show how the same operations look in both databases, so you can judge which query style fits your team and workload. For complete operator reference, see the PostgreSQL JSONB documentation and the MongoDB query operator reference.
Querying nested JSON fields
-- PostgreSQL: find orders where the shipping address is in California
SELECT id, data->>'customer_name' AS customer
FROM orders
WHERE data->'shipping'->'address'->>'state' = 'CA'
AND (data->>'total')::numeric > 100
ORDER BY created_at DESC
LIMIT 20;
-- PostgreSQL: containment query (uses GIN index)
SELECT id, data
FROM orders
WHERE data @> '{"status": "shipped", "priority": "high"}'::jsonb;// MongoDB: same query - find orders shipped to California
db.orders.find({
"shipping.address.state": "CA",
"total": { $gt: 100 }
}).sort({ created_at: -1 }).limit(20);
// MongoDB: equivalent containment-style query
db.orders.find({
status: "shipped",
priority: "high"
});Indexing strategies compared
-- PostgreSQL: GIN index for containment queries
CREATE INDEX idx_orders_data ON orders
USING GIN (data jsonb_path_ops);
-- PostgreSQL: expression index for a specific hot path
CREATE INDEX idx_orders_status ON orders ((data->>'status'));
-- PostgreSQL: composite expression index
CREATE INDEX idx_orders_tenant_status ON orders (
(data->>'tenant_id'),
(data->>'status'),
created_at DESC
);
-- Check if your index is actually being used
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM orders
WHERE data->>'status' = 'pending'
ORDER BY created_at DESC LIMIT 10;// MongoDB: compound index (equivalent strategy)
db.orders.createIndex(
{ "tenant_id": 1, "status": 1, "created_at": -1 }
);
// MongoDB: check index usage with explain
db.orders.find({
status: "pending"
}).sort({ created_at: -1 }).limit(10).explain("executionStats");
// MongoDB: wildcard index (use sparingly)
db.orders.createIndex({ "data.$**": 1 });
// Warning: wildcard indexes grow fast on write-heavy collectionsNotice how PostgreSQL requires explicit casting and operator awareness (the ->> vs -> distinction matters for indexing), while MongoDB queries read more naturally but hide index complexity behind the driver. The MongoDB server source code on GitHub documents the query planner internals if you want to understand why certain index strategies outperform others.
Keep Reading
Related Reading
- PostgreSQL vs MySQL: 2026 Decision Framework — The production database choice
- PostgreSQL Performance in 2026 — The tuning guide that matters
- Docker vs Kubernetes in Production (2026) — The deployment architecture decision
- Python 3.12 vs 3.13 vs 3.14 Comparison — Which Python version to use in production
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Plan your upgrade path with breaking change warnings and step-by-step guidance.
Check extension compatibility across PostgreSQL versions.
Track These Releases