Kubernetes 1.36 upgrade preview: community says “fix your AppArmor YAML now”
Reddit’s already arguing about this one. Not because 1.36 ships shiny toys, but because it yanks crutches people still depend on.
Community take: what people are complaining about right now
I’ve watched the same three threads repeat across Slack and Discord: “apiserver says Ready but my controllers act drunk,” “why is AppArmor still an annotation in our Helm chart,” and “why did kubectl suddenly say ‘no matches for kind’ after an upgrade?”
Most teams who track upstream closely seem to be upgrading their test clusters as soon as betas land. They want the breakage to happen on a weekday, in staging, with coffee.
- Watch behavior at startup still bites: As one SRE put it, “Ready means ‘load balancer can send traffic,’ not ‘the caches you rely on exist yet.’” The 1.36 change tries to make that gap smaller, but you still need to test your controllers.
- AppArmor cleanup moved from “someday” to “now”: Folks keep finding the legacy annotation in copied YAML, old Helm charts, and in-house generators. That stuff tends to hide until the night you roll a node pool.
- API removals break pipelines first: Running workloads might keep humming, then your deploy job fails with “no matches for kind” and you cannot ship a hotfix. That’s how you earn the 2 AM page.
Official changelog, trimmed to the parts that break you
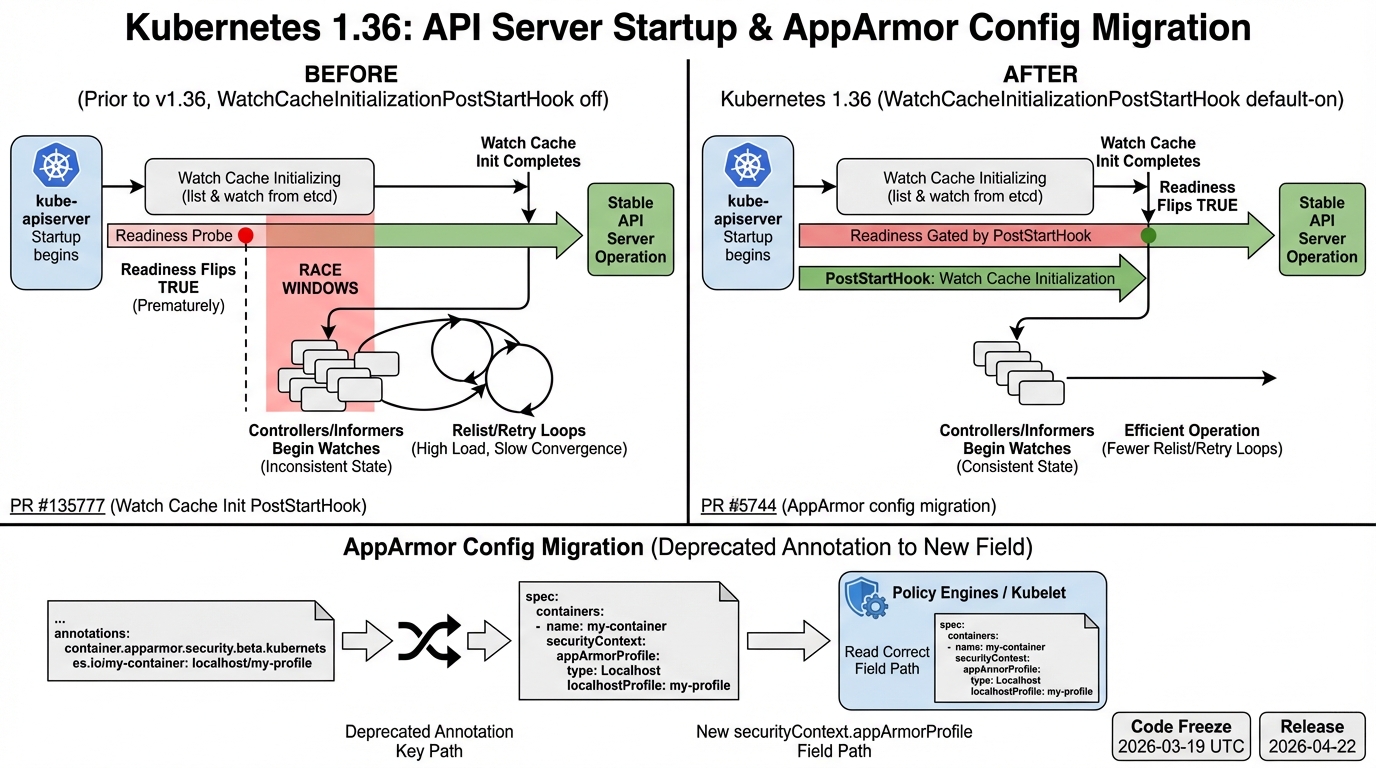
Watch cache init happens before apiserver reports Ready
This change has a paper trail you can actually point to in a PR review: kubernetes/kubernetes PR #135777, plus kubernetes/enhancements PR #5744. It enables the WatchCacheInitializationPostStartHook path by default in 1.36, which means the apiserver holds readiness until builtin watch caches initialize.
Good. Mostly.
The consensus seems to be that this reduces a whole class of “startup roulette” bugs. Some teams report fewer early watch/list weirdness after control plane restarts, others say their controllers still need sane retry logic because reality stays messy.
AppArmor annotation support heads toward the exit
The thing nobody mentions until it hurts: your cluster can “enforce AppArmor” and still accept manifests that talk to the wrong field. Kubernetes introduced the real field, securityContext.appArmorProfile, back in v1.30 per the AppArmor KEP (sig-node KEP-24). 1.36 targets the end of annotation-based compatibility behavior.
So. If you still ship YAML that uses container.apparmor.security.beta.kubernetes.io/*, treat that as a bug, not “legacy support.” I don’t trust “we’ll migrate later” on security controls. It always slips.
- Policy drift looks like safety: Admission and policy engines sometimes validate the old annotation while runtime enforcement reads the new field. You get green checks and unconfined pods. That’s not a theoretical risk. It’s a common miswire.
- Old tooling fails at deploy time: You merge a chart, CI looks fine, then kubectl apply fails in prod because the API no longer accepts what you sent. That’s the worst failure mode.
resource.k8s.io/v1beta1 goes away in 1.36
If your CI applies manifests using resource.k8s.io/v1beta1, plan on hard failures once you land on 1.36. The migration path points to v1beta2, and vendors already treat this as a deletion, not a “maybe.”
Some folks hand-wave API removals because “the cluster keeps running.” I get it. Your pipeline will not.
My synthesis: why 1.36 feels “small” but acts sharp
Kubernetes keeps moving from “eventually consistent glue” to “the control plane makes stronger promises.” The watch cache gating change is part of that, and I’m glad the maintainers spend time on determinism instead of adding another checkbox feature nobody can support.
On the security side, this AppArmor shift follows the usual arc. Annotation hack first, real field next, years of compatibility, then the delete. If you run multi-tenant clusters and you still treat security fields like optional metadata, do not do that.
Most teams are upgrading, but the smart ones run a preflight that fails CI on deprecated APIs and legacy AppArmor annotations.
What I’d do this week (consensus-driven, not heroics)
Run three checks. Fix what you find.
- Scan your repos for AppArmor annotations: rg -n “container.apparmor.security.beta.kubernetes.io” .
- Block v1beta1 usage in CI: grep for “resource.k8s.io/v1beta1” in rendered manifests, Helm output, and kustomize builds. Do not wait for the cluster upgrade to tell you.
- Test a control plane restart with your real controllers: Restart the apiserver in a staging cluster if you can, then watch controller logs for hot loops. Your code should handle retries anyway.
Other stuff in this release: dependency bumps, some image updates, the usual. There’s probably a better way to test watch behavior than “bounce the control plane and stare at logs,” but that’s what most teams actually do.
Anyway. If you only take one action, kill the AppArmor annotation in your YAML. That’s the one that keeps showing up in “why did this break” threads.
🔍 Free tool: K8s YAML Security Linter — paste any Kubernetes manifest and instantly catch security misconfigurations: missing resource limits, privileged containers, host network access, and more.
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.
Track These Releases