Kubernetes v1.36.0 makes external token signing feel real
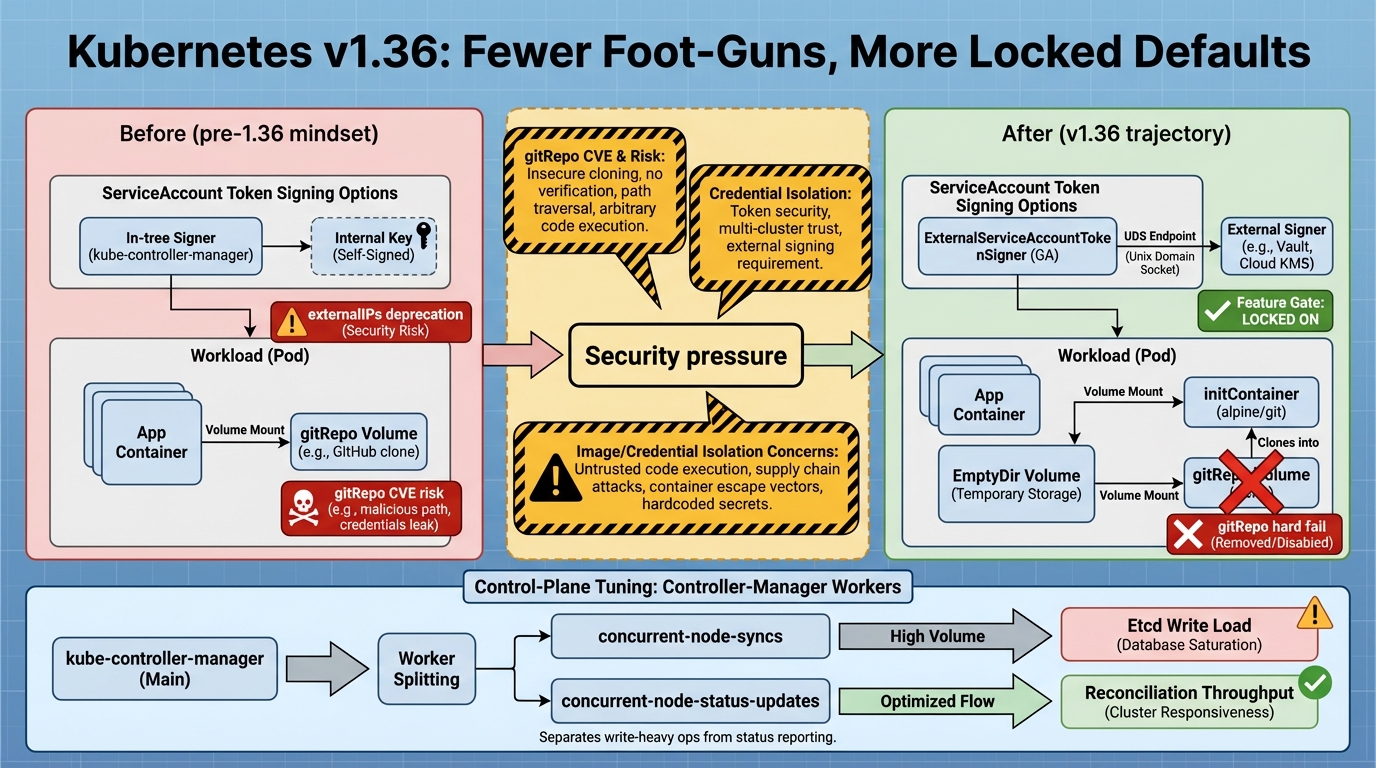
ExternalServiceAccountTokenSigner goes GA in v1.36.0, and I love this change because it turns a hacky compliance workaround into something you can run with a straight face in staging.
Highlights you should care about first
I’ve watched teams duct-tape ServiceAccount token signing to satisfy “keys must live in an HSM” requirements, then spend the next six months acting surprised when rotation day turns into a high-stress incident. Now you get a supported path, with a feature gate that stops being optional, and that’s exactly the kind of boring improvement that keeps clusters calm at 2 a.m.
Good news. Real consequences.
- ExternalServiceAccountTokenSigner is GA and stays on: v1.36.0 promotes it and locks the gate enabled-by-default, so the “maybe later” era ends and the “operate this like a dependency” era begins.
- Service.spec.externalIPs starts its exit: v1.36.0 deprecates externalIPs, which means the easy networking escape hatch becomes a migration project you can schedule, not a mystery you inherit.
- gitRepo finally gets put down: v1.36.0 continues the push away from the in-tree gitRepo volume, and if you still rely on it, staging will catch it fast because pods stop starting.
- Controller-manager gets a better knob: a new flag splits node status write concurrency from node sync work, so large clusters can stop choosing between stale node conditions and angry etcd disks.
Deep dive 1: ExternalServiceAccountTokenSigner GA means you own the signer
This bit me once in a different form: we moved “one more thing” out of the API server, then forgot we had created a new critical path. It worked great until the signer endpoint added 80 ms of latency during a quiet deploy, and suddenly controllers started throwing 401s in logs that looked totally unrelated.
Here’s the shift: the API server still serves requests, but token issuance and verification now depend on your signer endpoint’s latency and uptime. You probably want to treat that endpoint like a tier-0 component, even if it lives on a Unix domain socket and feels “local.” Early signs look good, but I haven’t stress-tested every environment or every managed distro yet.
- What gets better versus older versions: remember when you had to say “yes it’s experimental, but trust us” to your security team? Now you can point to GA behavior and build real runbooks around it.
- What can get worse if you wing it: when auth breaks, everything looks guilty. Controllers flap, webhooks fail, kubelet screams about authz, and you waste 45 minutes until you correlate timelines across components.
- What I’d test in staging: cut the signer endpoint’s availability for 60 seconds and watch for controller 401 or 403 spikes, then rotate keys on purpose and confirm the cluster keeps accepting new tokens without a wave of restarts.
If you externalize signing, write an SLO for it. Do not call it “just a socket” and hope for the best.
Deep dive 2: externalIPs deprecation forces a networking decision
I get why externalIPs stuck around. Someone needed a thing reachable on a specific IP, and externalIPs looked like a clean YAML-only solution. It also let people bypass your platform’s intended exposure paths, and that “flexibility” tends to show up later as a security review with a raised eyebrow and a spreadsheet of Services nobody owns.
So, v1.36.0 puts externalIPs on the conveyor belt toward removal. Your best move is to pick your sanctioned exposure mechanisms and enforce them with policy, because “everyone knows not to use externalIPs” stops working the moment a contractor ships a Helm chart on a Friday afternoon.
- If you run managed Kubernetes: assume your provider will enforce the upstream direction, and probably on their timeline, not yours.
- If you run bare metal: you might replace externalIPs with something explicit like MetalLB or a gateway pattern, where ownership and routing live somewhere you can audit.
- If you do nothing: you will eventually discover an externalIP during an incident, when somebody realizes the service “only breaks sometimes” because the routing assumption lived in someone’s head.
Deep dive 3: gitRepo volumes, CVEs, and the nicest kind of failure
The thing nobody mentions until it hurts: legacy charts linger forever. You upgrade the platform, everything looks green, then one dusty app deploys a Pod with a gitRepo volume and kubelet refuses to run it. That failure feels rude, but it is the right kind of rude.
gitRepo has a long security paper trail, including CVE-2025-1767, and upstream has been pushing everyone toward safer patterns. The replacement looks boring in the best way: clone in an initContainer (or git-sync), write into an EmptyDir, and mount that directory in your main container. You can log it, scan it, and reason about it.
- What I’d do before upgrading: scan manifests and Helm output for gitRepo usage, because it only takes one chart to surprise you.
- What I’d accept as a fix: initContainer clones into EmptyDir, main container mounts it read-only, and the app starts without kubelet volume plugin drama.
- What I would not accept: “we’ll keep the old chart around” in any cluster you call production.
Deep dive 4: controller-manager tuning finally separates two kinds of work
I’ve seen operators tweak concurrent-node-syncs trying to fix delayed node conditions, then accidentally crank etcd write pressure until apiserver requests start timing out. That’s not operator error, it’s a knob that tried to control two different loads with one number.
v1.36.0 adds –concurrent-node-status-updates so you can tune node status writes separately from node sync reconciliation work. Large clusters get a real lever here. Small clusters should probably leave it alone, unless you enjoy chasing the kind of timing bug that disappears the moment you add logging.
- Large clusters: change one flag at a time, watch etcd write latency, then wait long enough for the control plane to settle before you touch anything else.
- Small clusters: stick with defaults until you have a metric that proves you need tuning.
Migration notes and how to test without donating your weekend
Test it. Soon.
Pick a disposable environment and run the beta or RC line there first. I like staging for this because you get real controllers, real admission webhooks, and real “why did this request get a 403” moments, without the pager fallout. Some folks skip canaries for patch releases. I do not, and v1.36.0 is not a patch release.
- Kind (local): create a cluster using a v1.36 beta node image tag that actually exists in your environment. Verify with a quick pull first, because image tags change and docs rot.
- kubeadm (lab): run kubeadm init with –kubernetes-version v1.36.0-beta.0, and pre-pull images so you do not discover registry problems halfway through a test window.
Red flags to grep before you declare victory
- gitRepo fallout: kubelet errors admitting or running pods that reference gitRepo volumes. Treat this as a blocker, fix the charts, rerun.
- Token signer problems: apiserver authn or authz errors that line up with signer endpoint health, plus controller logs showing new 401 or 403 spikes.
- externalIPs drift: admission denials if you enforce policy, or surprise exposure patterns if you do not.
- Node status churn: increased etcd write latency, apiserver request timeouts, or node conditions that update slower after you tune concurrency.
Other stuff in this release: dependency bumps, some image updates, the usual. There’s probably a cleaner one-liner for the whole story, but v1.36.0 really comes down to this: clean up the legacy defaults now, while you still control the timeline.
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.