PostgreSQL vs MySQL in 2026: Pick Your Failure Mode
I’ve watched “database selection” turn into an on-call problem six months later.
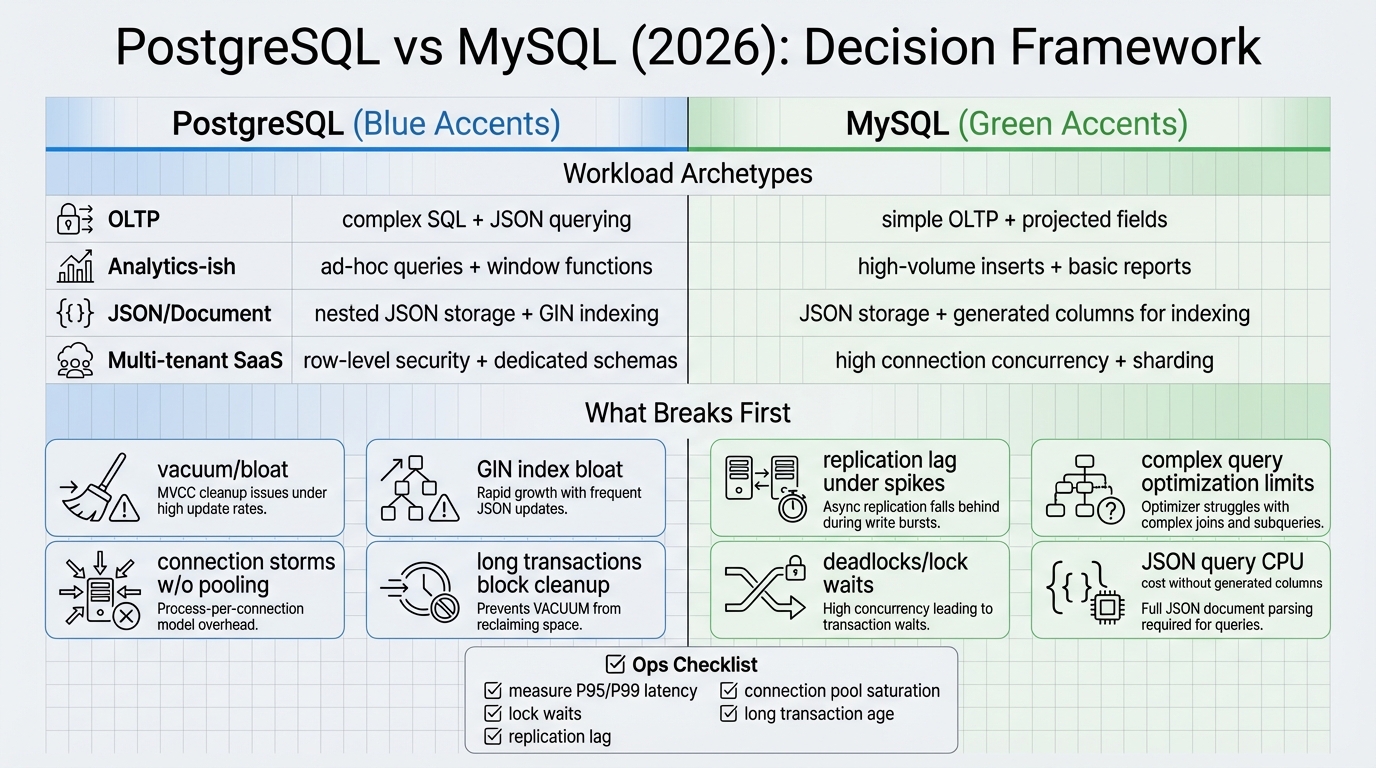
PostgreSQL vs MySQL in 2026 doesn’t come down to a checklist of features. It comes down to which kind of pain you can live with under load: lock waits, replication lag, vacuum or purge pressure, connection storms during deploys, or schema changes that block writes at the worst moment.
The 10-minute decision: what will break first?
Pick the database by answering one question.
What gets painful first as your service grows: correctness under concurrency, or operations under churn? Both engines store JSON. Both run OLTP. The split shows up when you mix workloads, evolve schemas every week, and ship code that restarts pods all day.
- Default to PostgreSQL: when you expect complex queries, queryable JSON, database-enforced tenant isolation, or “reporting on prod” creep.
- Default to MySQL (InnoDB): when you can keep the workload clean OLTP, your team already runs MySQL well, and you will push analytics elsewhere on purpose.
If you cannot describe your workload in one sentence, you probably want PostgreSQL. If you can, and it’s pure CRUD, MySQL stays boring in a good way.
Workload archetypes (the stuff I see teams trip on)
This bit me when a “simple CRUD” service turned into a dashboard factory.
The team started with clean endpoints and tight indexes. Six product requests later, they added rollups, ad-hoc filters, and JSON flags. The database never “got slow” in a benchmark. It got weird at p99 during peak traffic.
- Straight OLTP, simple joins: PostgreSQL usually hits connection pressure and vacuum tuning earlier. MySQL usually stays smooth until query shapes drift into complex joins and reporting.
- OLTP plus analytics-ish reads on the primary: PostgreSQL gives you more SQL tools, but heavy queries can spike latency and push replicas behind. MySQL works if you offload analytics early and actually follow through.
- JSON-heavy where JSON appears in WHERE clauses: PostgreSQL tends to win on queryability, but GIN indexes can bloat and vacuum has to keep up. MySQL tends to push you toward generated columns and “real columns,” which is boring and often correct for OLTP.
- Multi-tenant SaaS: PostgreSQL’s row-level security can enforce tenant rules in the database. MySQL can work if you isolate tenants by schema or database, but app-layer mistakes cause the ugliest incidents.
- High-write ingestion: both engines hate “too many secondary indexes.” PostgreSQL adds vacuum and bloat into the mix. MySQL adds replica lag and secondary index cost under sustained writes.
Concurrency and performance: ignore microbenchmarks
Fast queries don’t save you.
Most greenfield services lose to one of four patterns: 500 pods reconnecting at once, one hot row everybody updates, an index explosion on a write-heavy table, or a “helpful” transaction that holds locks far longer than anyone admits.
Hot rows: fix the pattern before you blame the engine
So.
If you run a global counter, or you update “last_seen” on every request, you will create a tiny little traffic jam inside any relational database. PostgreSQL and MySQL both fight you here. The fix usually lives in your data model, not in a config file.
- Prefer append-only writes: write an event row, aggregate later. Your disks stay busy, but your locks stay calmer.
- Shard counters: keep N counters per tenant and sum them. It looks silly until you see the p99 line flatten.
- Keep transactions tiny: one request, one short transaction. Do not hold locks while you call another service.
Isolation: check defaults, then choose on purpose
Defaults vary more than people admit.
PostgreSQL typically runs READ COMMITTED by default, and InnoDB commonly runs REPEATABLE READ by default, but managed services sometimes change settings. Pick isolation levels per workload, then write tests that try to break your invariants under concurrency. If you do not test it, you do not have it.
JSON in 2026: “payload” vs “query model”
The thing nobody mentions is the maintenance bill.
Queryable JSON feels cheap on day 1. On day 90, your index grows teeth, autovacuum works overtime, and the team starts arguing about whether that JSON field “really needs to be updated so often.”
- Pick PostgreSQL for queryable JSON: when you filter, join, or aggregate on nested JSON fields and need serious indexing options.
- Pick MySQL when JSON stays a payload: when you store JSON for convenience but promote the few real filter/sort fields into generated or extracted columns early.
My strong opinion: JSON should earn its place in your WHERE clause. Otherwise, keep it as a blob and move on.
Ops: the boring stuff that pages you
Failover rarely fails in the database.
Failover fails in clients. Pools keep dead connections, retries stampede the new primary, and your “idempotent” handler double-charges someone. Practice failover with the real app, not just a database health check.
- Replication lag: plan for it. If you need read-your-writes, pin to the primary or build session consistency.
- Schema changes: test them on production-sized data. Some DDL takes locks. Some “online” changes still hurt depending on the exact operation and version.
- Maintenance reality: PostgreSQL needs vacuum to keep up. MySQL needs disciplined indexing and InnoDB tuning. Neither is “set and forget.”
What to measure before you commit
Run one realistic load test.
Use production-like concurrency, data size, and a deploy-style reconnect storm. Then measure p95 and p99 latency, lock waits, deadlocks, and replica lag. Watch what breaks first. That’s your answer.
- Workload shape: read/write ratio by endpoint, rows touched per transaction, longest transaction duration.
- Contention: lock wait time, deadlock rate, hot indexes that get hammered by updates.
- Client churn: peak concurrent connections during deploy, pool exhaustion rate, retry storm behavior during failover.
Deployment: managed vs Kubernetes (pick your battles)
Managed databases usually win.
If you run Postgres or MySQL inside Kubernetes, you are building a database platform. Operators help, but you still own volume performance, backups that actually restore, split-brain avoidance, and client reconnection behavior during node maintenance. I don’t trust “Kubernetes makes it portable” for stateful data. Incident response eats that story alive.
- High churn apps: cap connections and fail fast. Add a proxy or pooler if you need it.
- Node/Python/Go: pools matter more than driver choice. Forking models matter. Timeouts matter.
Migration and making the choice reversible
Don’t start with a benchmark suite.
Start by keeping the decision reversible. Keep SQL conservative, isolate dialect-specific bits behind a module, and plan for data export. If you bet on PostgreSQL features like RLS or heavy jsonb indexing, migration gets expensive. If you bet on MySQL staying pure OLTP, do not let the workload quietly turn into a mini-warehouse.
Other stuff in this release: dependency bumps, some image updates, the usual.
Bottom line
Pick PostgreSQL when you expect your workload to evolve into complex queries, queryable JSON, or database-enforced multi-tenant controls.
Pick MySQL when you can keep it disciplined OLTP, you have MySQL muscle memory, and you will offload analytics instead of pretending you will later.
Answer two questions after one real load test: what breaks first under concurrency, and what will your team debug at 02:00 during failover?
Connection handling: where MySQL quietly wins small deployments
PostgreSQL forks a process per connection. MySQL uses threads. At 50 connections this barely matters. At 500 connections without a pooler, PostgreSQL eats RAM and context-switches itself into latency spikes.
- PostgreSQL: You need PgBouncer or Pgpool-II in front of it for any serious workload. Transaction-level pooling is the sane default. If your framework holds connections open (looking at you, Rails), set idle_in_transaction_session_timeout or you will run out of connections during a deploy.
- MySQL: Thread-per-connection handles more clients out of the box. InnoDB’s adaptive hash index helps with repeated point lookups. For a simple CRUD app with 200 concurrent users, MySQL works without a connection pooler. PostgreSQL needs one.
- The real lesson: Both databases handle thousands of queries per second on modest hardware. The difference is operational overhead. If your team does not want to manage PgBouncer, MySQL costs less human time.
Backup and disaster recovery: test it or it does not exist
Every team has backups. Almost nobody tests restores. The database you can restore fastest is the safer choice for your team.
- PostgreSQL backup options: pg_dump for logical backups (slow for large databases, but easy). pg_basebackup + WAL archiving for point-in-time recovery (PITR). Barman or pgBackRest for production-grade automated backups with retention policies. If you self-host, set up continuous archiving on day one. If you use RDS or Cloud SQL, enable automated backups and test a restore quarterly.
- MySQL backup options: mysqldump (same trade-offs as pg_dump). Percona XtraBackup for hot physical backups without locking InnoDB. MySQL Enterprise Backup if you pay for it. Binlog-based PITR works but requires careful binlog retention settings. Most teams use mysqldump and hope. Do not be most teams.
- The test that matters: Spin up a blank instance, restore from your latest backup, and verify data integrity. Time it. If it takes longer than your RTO, your backup strategy is a fiction. Run this test monthly, automated if possible.
Ecosystem and tooling: what your team already knows matters
Technical superiority means nothing if your team fights the tooling. The database your engineers have production experience with is almost always the right choice for a new project.
- PostgreSQL ecosystem: Extensions are the killer feature. PostGIS for geospatial, pg_cron for scheduled jobs, pgvector for embeddings, TimescaleDB for time-series. The extension model means PostgreSQL adapts to new workloads without bolting on extra services. The trade-off is that some extensions lag behind major version upgrades.
- MySQL ecosystem: Broader hosting support (every cheap shared host runs MySQL). WordPress, Drupal, and most PHP frameworks default to MySQL. Percona and MariaDB offer drop-in alternatives with specific improvements. ProxySQL for advanced routing. Vitess if you genuinely need horizontal sharding (but you probably do not yet).
- ORMs and frameworks: Django’s ORM works better with PostgreSQL (native JSONField, ArrayField, full-text search). Laravel works equally well with both. Rails has strong PostgreSQL support but some gems assume MySQL syntax. Node.js ORMs (Prisma, Drizzle, TypeORM) support both, but check the migration tooling — some generate slightly different DDL per dialect.
Side-by-side: common operations in PostgreSQL vs MySQL
Syntax differences matter more than people admit. Here are common production operations shown side-by-side so you can see where the databases diverge. For full syntax reference, see the PostgreSQL SQL command reference and the MySQL SQL statement reference.
Connection pooling configuration
# PostgreSQL: PgBouncer config (pgbouncer.ini)
# Without a pooler, PG forks a process per connection
[databases]
myapp = host=127.0.0.1 port=5432 dbname=myapp
[pgbouncer]
listen_addr = 0.0.0.0
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
pool_mode = transaction # Key: transaction-level pooling
default_pool_size = 25 # Per user/database pair
max_client_conn = 1000 # Accept up to 1000 app connections
max_db_connections = 50 # But only 50 real PG connections
server_idle_timeout = 300
query_wait_timeout = 120-- MySQL: connection tuning (no external pooler needed for most workloads)
-- MySQL uses threads, not processes, so it handles more connections natively
SET GLOBAL max_connections = 500;
SET GLOBAL thread_cache_size = 50;
SET GLOBAL wait_timeout = 300;
SET GLOBAL interactive_timeout = 300;
-- Check current connection usage
SHOW STATUS LIKE 'Threads_connected';
SHOW STATUS LIKE 'Max_used_connections';
-- ProxySQL for MySQL (when you DO need a pooler at scale)
-- ProxySQL sits between app and MySQL, routes read/write traffic
-- Config is stored in a SQLite database:
-- INSERT INTO mysql_servers (hostgroup_id, hostname, port)
-- VALUES (0, 'mysql-primary', 3306), (1, 'mysql-replica', 3306);JSON handling: queryable vs payload
-- PostgreSQL: JSON as a queryable first-class type
SELECT id, config->>'theme' AS theme
FROM user_settings
WHERE config @> '{"notifications": true}'::jsonb
AND (config->>'seats')::int > 5;
-- GIN index makes this fast
CREATE INDEX idx_settings_config ON user_settings
USING GIN (config jsonb_path_ops);
-- ------------------------------------------
-- MySQL: JSON with generated columns (the practical pattern)
SELECT id, JSON_EXTRACT(config, '$.theme') AS theme
FROM user_settings
WHERE JSON_CONTAINS(config, 'true', '$.notifications')
AND JSON_EXTRACT(config, '$.seats') > 5;
-- MySQL: promote hot JSON paths to generated columns for indexing
ALTER TABLE user_settings
ADD COLUMN notifications BOOLEAN GENERATED ALWAYS AS (JSON_EXTRACT(config, '$.notifications')) STORED,
ADD INDEX idx_notifications (notifications);Replication setup comparison
-- PostgreSQL: streaming replication (primary side)
-- postgresql.conf on primary:
-- wal_level = replica
-- max_wal_senders = 5
-- wal_keep_size = 1GB
-- Check replication status on primary
SELECT
client_addr,
state,
sent_lsn,
write_lsn,
flush_lsn,
replay_lsn,
sent_lsn - replay_lsn AS replication_lag
FROM pg_stat_replication;
-- ------------------------------------------
-- MySQL: check replica status
SHOW REPLICA STATUS\G
-- Key fields to watch:
-- Seconds_Behind_Source: 0 (lag in seconds)
-- Replica_IO_Running: Yes
-- Replica_SQL_Running: Yes
-- MySQL: GTID-based replication (modern setup)
-- my.cnf on primary:
-- gtid_mode = ON
-- enforce_gtid_consistency = ON
-- binlog_format = ROW
-- log_replica_updates = ONThese examples highlight a key difference: PostgreSQL gives you more power out of the box (JSONB operators, streaming replication monitoring), while MySQL pushes you toward simpler patterns (generated columns for JSON, GTID for replication) that are often the right choice for straightforward workloads. The development of both databases can be tracked through their respective repositories: PostgreSQL on GitHub for tracking planner and storage engine changes.
Keep Reading
Frequently Asked Questions
- Should I use PostgreSQL or MySQL for a new project in 2026? Default to PostgreSQL unless you have a specific reason not to. It handles more workload patterns (JSON, full-text search, geospatial, complex queries) without plugins. MySQL wins when you need simpler replication, have a WordPress/LAMP stack, or your team already knows it deeply. The wrong database is the one nobody on your team can operate at 3 AM.
- Is PostgreSQL faster than MySQL? Microbenchmarks are misleading. PostgreSQL is typically faster for complex joins, CTEs, and analytical queries. MySQL is faster for simple primary key lookups and high-throughput writes with minimal locking. What matters more than raw speed is your concurrency pattern — PostgreSQL’s MVCC handles mixed read-write workloads more gracefully than MySQL’s default isolation level.
- Can I use PostgreSQL as a JSON document store instead of MongoDB? Yes, and increasingly teams are doing exactly that. PostgreSQL’s jsonb type with GIN indexes handles document queries efficiently. The advantage over MongoDB is you keep ACID transactions, joins, and a single operational stack. The disadvantage: if 95% of your access is document-shaped with no cross-document queries, MongoDB’s native model is simpler.
- Which database is easier to operate on Kubernetes? Both have mature operators — CloudNativePG for PostgreSQL and MySQL Operator for Oracle MySQL / Percona XtraDB Cluster. PostgreSQL is slightly ahead in the Kubernetes ecosystem (more operators, better community docs). For either, use a managed service (RDS, Cloud SQL) unless you have a dedicated platform team. Running databases on Kubernetes is not hard — recovering from split-brain at 2 AM is.
Related Reading
- PostgreSQL vs MySQL: 2026 Decision Framework — The production database choice
- PostgreSQL vs MongoDB for JSON Workloads — When your problem is the data model
- PostgreSQL Performance in 2026 — The tuning guide that matters
- Docker vs Kubernetes in Production (2026) — The deployment architecture decision
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.
Track These Releases