Picking a database for a new service in 2026 is less about “features” and more about what fails first in production: write concurrency, query shape drift, operational ergonomics, and how painful the first schema evolution will be.
This framework treats PostgreSQL vs MySQL as an operator decision: score your workload, look for tipping points (JSON indexing, concurrency/locking behavior, replication/failover expectations), then validate with a small set of concrete EXPLAIN patterns and early-life metrics.
Contents
- Production-first decision rubric (workload scoring + tipping points)
- JSON & indexing in practice (JSONB vs MySQL JSON, GIN vs generated columns)
- Concurrency, locking, and “what hurts at scale”
- Query planning & EXPLAIN patterns to verify early
- Ops & reliability: backups/PITR, replication, failover, migrations
- First 30 days in production: metrics and alarms
- Migration path / getting started
Production-first decision rubric (workload scoring + tipping points)
Start by treating the database choice like capacity planning: define the dominant workload, then pick the engine that degrades more gracefully when your assumptions are wrong.
A quick baseline: when either is fine
If you have a classic OLTP service (orders, users, subscriptions), moderate concurrency, and you keep JSON usage light (payload storage, not query predicates), both PostgreSQL and MySQL will work. The decision is usually driven by team familiarity, managed service maturity in your cloud, and ecosystem (ORM defaults, extensions, tooling).
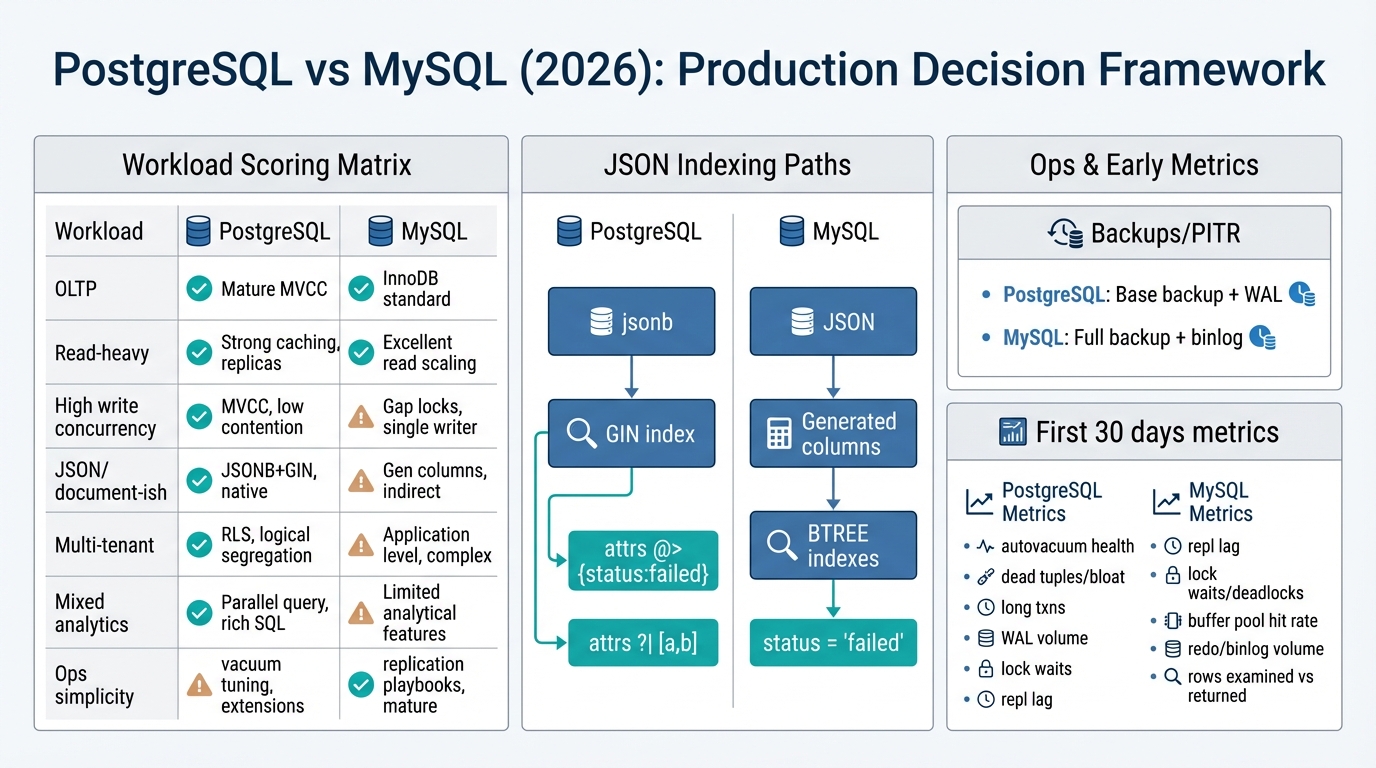
Workload scoring matrix
Score each row 0–3 based on how true it is for your service. Then apply the “tipping points” under the table.
| Dimension | What to score | PostgreSQL bias | MySQL bias |
|---|---|---|---|
| OLTP (mixed reads/writes) | Normalized schema, transactional integrity, frequent joins | Strong (planner, indexes, constraints, CTEs, window functions) | Strong (InnoDB is solid; simpler tuning for many OLTP cases) |
| Read-heavy | High QPS reads, cache misses hurt, replicas needed | Strong (replicas + query flexibility) | Strong (replication is widely used; easy read scaling patterns) |
| High write concurrency | Many concurrent writers, hotspots, high TPS | Often better behavior under contention (MVCC + tooling), but tune autovacuum | Can be excellent, but watch locking patterns and secondary index write amp |
| JSON/document-ish queries | Filtering/sorting on JSON fields, ad-hoc predicates, evolving schema | Clear edge (JSONB + GIN/operator classes) | Viable with generated columns + functional indexes; less flexible for ad-hoc |
| Multi-tenant | Row-level isolation, tenant-aware indexing, partitioning needs | Strong (RLS, partial indexes, partitions) | Strong (partitions + careful schema design), fewer built-in isolation features |
| Analytics mixed into OLTP | Occasional heavy queries against primary data | Usually safer (planner + indexing options); still use read replicas | Often fine, but more likely to need dedicated analytics path earlier |
| Operational simplicity | Small team, minimal tuning appetite | Managed Postgres is good; requires vacuum awareness | Often simpler mental model; still needs replication/backup discipline |
Tipping points (use these as hard decision triggers)
- JSON is part of your query API (filtering, containment, dynamic attributes) → default to PostgreSQL. You’ll ship fewer schema contortions.
- You need row-level security (RLS) as a first-class primitive for multi-tenant isolation → PostgreSQL.
- You expect very high read scaling with simple query patterns (key lookups, small range scans) and want the most standard replication playbook → MySQL is a safe default.
- Your write load is hotspot-heavy (single counter row, “latest events” table, contention on secondary indexes) → either can work, but you must test the exact pattern. PostgreSQL tends to give you more knobs and visibility; MySQL can be extremely fast when the access pattern matches InnoDB’s strengths.
- You want one engine for “SQL + weird queries” (text search, custom operators, partial indexes, advanced constraints) → PostgreSQL.
Official references: PostgreSQL documentation (JSON types, indexing, MVCC/vacuum) and MySQL documentation (InnoDB, JSON, generated columns, replication). See: postgresql.org/docs and dev.mysql.com/doc.
JSON & indexing in practice (JSONB vs MySQL JSON, GIN vs generated columns)
🔔 Never Miss a Breaking Change
Monthly release roundup — breaking changes, security patches, and upgrade guides across your stack.
✅ You're in! Check your inbox for confirmation.
Both databases can store JSON. The production difference is indexing flexibility and how often you’ll have to redesign when product adds “one more filter.”
PostgreSQL: JSONB + GIN for containment and ad-hoc predicates
Use jsonb when you need to query inside documents. A common pattern is “base columns for stable fields, JSONB for optional attributes.”
CREATE TABLE events (
id bigserial PRIMARY KEY,
tenant_id bigint NOT NULL,
created_at timestamptz NOT NULL DEFAULT now(),
type text NOT NULL,
attrs jsonb NOT NULL
);
-- Fast containment queries (attrs @> '{...}')
CREATE INDEX events_attrs_gin ON events USING gin (attrs);
-- Typical multi-tenant index
CREATE INDEX events_tenant_created_at ON events (tenant_id, created_at DESC);
Example query (containment + tenant scoping):
SELECT id, created_at
FROM events
WHERE tenant_id = $1
AND type = 'payment'
AND attrs @> '{"status":"failed"}'
ORDER BY created_at DESC
LIMIT 50;
What to watch:
- GIN index size and update cost. Great for read/query flexibility; it’s not free for write-heavy workloads.
- Operator choice matters (
@>,->,->>,?|, etc.). You need query discipline or you’ll miss indexes.
MySQL: JSON + generated columns for indexable paths
MySQL’s pragmatic approach for production is: extract the JSON paths you care about into generated columns, then index those columns. This is less flexible than GIN, but predictable.
CREATE TABLE events (
id bigint unsigned NOT NULL AUTO_INCREMENT,
tenant_id bigint NOT NULL,
created_at timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
type varchar(64) NOT NULL,
attrs json NOT NULL,
status varchar(32)
GENERATED ALWAYS AS (JSON_UNQUOTE(JSON_EXTRACT(attrs, '$.status'))) STORED,
PRIMARY KEY (id),
KEY events_tenant_created_at (tenant_id, created_at),
KEY events_status (status)
) ENGINE=InnoDB;
Example query:
SELECT id, created_at
FROM events
WHERE tenant_id = ?
AND type = 'payment'
AND status = 'failed'
ORDER BY created_at DESC
LIMIT 50;
Trade-off:
- When product adds
attrs.customer.segmentas a new filter, you’re doing a schema change (add generated column + index) instead of relying on a general-purpose JSONB index. - That schema change is operational work: online DDL strategy, replica lag during index build, and rollback planning.
Rule of thumb for JSON in 2026
- PostgreSQL when JSON is “query surface area” (customers filter/sort on it, internal tools build ad-hoc queries, schema evolves weekly).
- MySQL when JSON is “payload storage” and you can name the 3–10 JSON paths that matter for indexing.
Concurrency, locking, and “what hurts at scale”
The real production differences show up under contention: many writers, long transactions, and schema/index churn.
PostgreSQL: MVCC + vacuum is the price of predictable reads
Postgres uses MVCC; readers don’t block writers and writers don’t block readers (for normal DML). Under high churn, dead tuples accumulate and must be reclaimed. If vacuum/autovacuum can’t keep up, you’ll see bloat, rising latency, and eventually transaction ID wraparound pressure.
Common gotchas:
- Long-running transactions prevent vacuum from cleaning up. A “harmless” open transaction in a job worker can degrade the whole table.
- High update rate tables need tuned autovacuum settings (thresholds, scale factors) per table, not just global defaults.
Operational stance: Postgres is forgiving when you watch vacuum health; it’s punishing when you ignore it.
MySQL/InnoDB: locking is usually fine—until your access pattern isn’t
InnoDB also uses MVCC, but you’ll run into practical locking issues through next-key locks (to prevent phantom reads) and gap locks depending on isolation level and query shape. A missing index on an update/delete can turn into “why is the entire service stuck?”
Common gotchas:
- Updates without a good index can lock far more rows than you expect.
- Secondary index overhead in write-heavy tables: every secondary index is extra work on inserts/updates.
- Online DDL isn’t magic. Index builds and schema changes still create load and replica lag.
Concrete concurrency pattern: “claim a job” queue
This pattern is a concurrency litmus test.
PostgreSQL (SKIP LOCKED is first-class and widely used):
WITH next_job AS (
SELECT id
FROM jobs
WHERE run_at <= now() AND locked_at IS NULL
ORDER BY run_at
FOR UPDATE SKIP LOCKED
LIMIT 1
)
UPDATE jobs
SET locked_at = now(), locked_by = $1
WHERE id IN (SELECT id FROM next_job)
RETURNING *;
MySQL supports similar patterns in modern versions, but you must validate exact behavior under your isolation level and indexing. The production requirement is the same: correct indexes on the predicate and ordering keys; no table scans.
Query planning & EXPLAIN patterns to verify early
Don’t decide based on anecdotes. Run a representative subset of queries, then validate that the optimizer uses the indexes you think it will.
PostgreSQL: start with EXPLAIN (ANALYZE, BUFFERS)
EXPLAIN (ANALYZE, BUFFERS)
SELECT id
FROM events
WHERE tenant_id = 42
AND attrs @> '{"status":"failed"}'
ORDER BY created_at DESC
LIMIT 50;
What you want to see:
- Index scans on
(tenant_id, created_at)or a plan that uses the GIN index effectively (sometimes bitmap index scans). - Low “shared read” buffers after warmup (cache-friendly behavior).
- No unexpected sequential scans on large tables.
MySQL: use EXPLAIN ANALYZE and verify key usage
EXPLAIN ANALYZE
SELECT id
FROM events
WHERE tenant_id = 42
AND status = 'failed'
ORDER BY created_at DESC
LIMIT 50;
What you want to see:
- Chosen key matches your intended composite index, not a full scan.
- Rows examined is close to rows returned for selective predicates.
Indexing reality check: multi-tenant queries
If every query is tenant-scoped, your indexes should usually be tenant-prefixed. This is true in both engines, and it’s the most common “we built indexes but latency still sucks” mistake.
-- Postgres example
CREATE INDEX ON events (tenant_id, type, created_at DESC);
-- MySQL example
CREATE INDEX events_tenant_type_created_at ON events (tenant_id, type, created_at);
Ops & reliability: backups/PITR, replication, failover, migrations
This is where “new service” decisions usually bite: you don’t feel it on day 1, then you need a restore, a failover, or a migration and discover your assumptions were wrong.
Backups and point-in-time restore (PITR)
PostgreSQL PITR is built around base backups + WAL archiving. In managed services, PITR is usually a first-class feature. Operationally, you care about WAL volume and retention, and you test restores regularly.
MySQL PITR is typically built from full backups plus binary logs. Again, managed services usually package this nicely, but you still need to verify restore time objectives and binlog retention.
Production rubric:
- If your RPO/RTO is strict, pick the managed offering where you can actually test restores in automation without heroics.
- Measure restore time on realistic dataset size. “We have backups” is not a plan.
Replication and failover
Both ecosystems have mature replication. The differences are in your operational comfort:
- PostgreSQL: streaming replication is straightforward; failover tooling varies (managed services simplify this a lot). Read replicas are common; logical replication is a strong option for migrations and selective replication.
- MySQL: replication is ubiquitous and well-understood in industry. Topologies (primary/replica, semi-sync, group replication depending on distro) matter; your managed platform’s implementation details matter more than the engine marketing.
Schema migrations and “blast radius”
Two categories matter: (1) adding/removing indexes, (2) changing column types/rewrites.
PostgreSQL notes:
CREATE INDEX CONCURRENTLYavoids blocking writes but takes longer and has failure modes you need to handle in migrations.- Some ALTERs rewrite the table; plan those like deployments.
MySQL notes:
- Online DDL capabilities are good in modern MySQL/InnoDB, but large index builds still create load, IO pressure, and replica lag. Treat them as events.
- Generated columns for JSON indexing add migration overhead as your filter set evolves.
What makes migrations risky
- Heavy secondary indexing + write load: migration steps compete with production writes.
- Large tables without partitioning strategy: backfills and index builds become multi-hour events.
- Long transactions: in Postgres they block vacuum cleanup; in MySQL they can amplify lock contention.
Related ReleaseRun reading for production lifecycle planning:
When to Use PostgreSQL vs MySQL
| Scenario | Pick PostgreSQL when… | Pick MySQL when… |
|---|---|---|
| Classic service OLTP | You expect complex queries/joins to grow over time | You want a conservative, widely deployed OLTP default with simple access patterns |
| JSON-heavy product surface | JSON fields are frequently filtered, combined, and changed | JSON is mostly storage; indexed paths are stable and known |
| Multi-tenant B2B | You want RLS, partial indexes, and strong tenant isolation primitives | You use schema-per-tenant or strict tenant-prefixed indexing and keep it simple |
| High write concurrency | You need strong visibility and control (vacuum tuning, index choices like partial/GIN) | Your workload is predictable and you’re disciplined about indexes and isolation settings |
| Ops team maturity | You can operationalize vacuum monitoring and query plan hygiene | You prefer the most common operational playbooks and simpler baseline tuning |
First 30 days in production: what to measure
This is the stuff that tells you you’re headed for pain while you can still change course.
PostgreSQL: metrics and alarms
- Autovacuum health: dead tuples/bloat indicators, autovacuum runs, tables that never get vacuumed.
- Transaction age: long-running transactions; max transaction age per DB.
- WAL volume: spikes after deploys/backfills; WAL retention risk for replicas/PITR.
- Lock waits: blocked DDL, hot table contention.
- Replication lag (if using replicas): bytes/seconds behind.
MySQL: metrics and alarms
- Replication lag: seconds behind source; watch during index builds and backfills.
- Lock waits / deadlocks: surface missing indexes and bad transaction scoping early.
- Buffer pool hit rate: memory sizing and working set fit.
- Redo/binlog volume: spikes from migrations or batch writes.
- Rows examined vs rows returned: proxy for “queries are drifting away from indexes.”
If you don’t have time to instrument both deeply, that’s also a signal: pick the engine your team already knows how to run under incident pressure.
What Version Health Data Tells Us About Database Adoption
Our badge service tracks version health across 300+ technologies, including both PostgreSQL and MySQL. PostgreSQL accounts for 3% of all badge requests and is our fifth most-checked technology overall.
- PostgreSQL health checks outnumber MySQL checks roughly 3:1. This isn’t a popularity contest (MySQL still has massive deployment numbers), but it suggests PostgreSQL teams are more version-conscious. They check EOL dates and CVE status more actively.
- PostgreSQL’s version-specific checks cluster around the latest two major versions — consistent with the community’s advice to stay within 1-2 versions of current. MySQL checks are more spread out across versions, suggesting longer upgrade cycles.
- Both databases show a long tail of old version checks — teams running versions well past EOL that still want to know their risk exposure. If that’s you, our Dependency EOL Scanner will flag it.
The pattern is clear: PostgreSQL teams tend to upgrade more frequently and monitor more actively. Whether that’s because of the community culture, the faster release cadence, or the types of workloads using each database is hard to say from badge data alone. But if you’re choosing between the two for a new project, knowing that PostgreSQL’s community leans toward staying current is a relevant signal about long-term maintenance expectations.
Migration Path / Getting Started
A practical way to make this decision without a months-long benchmark project:
1) Define 10 “production truth” queries and 3 write patterns
- 5 read queries that hit your hottest endpoints
- 3 list queries with sorting/pagination
- 2 reporting-style queries that product will inevitably ask for
- Write patterns: insert-only, update-heavy, and one contention-prone pattern (job queue, counters, upserts)
2) Implement both schemas with realistic indexing
- Postgres: model stable fields as columns; JSONB for flexible attributes; add the GIN index only if JSON is queried.
- MySQL: decide the JSON paths that are queryable; implement generated columns + indexes for those paths.
3) Run load for concurrency and tail latency, not just throughput
Measure p95/p99 latency under concurrency and background load (migrations, index builds, backfills). Throughput-only tests pick the wrong winner.
4) Validate restore and replica behavior
- Practice PITR to an arbitrary timestamp in a staging environment.
- Simulate failover and measure client impact (connection errors, transaction retries, timeouts).
5) Decide how you’ll change your mind later
If there’s a real chance you’ll need to switch engines, plan for it up front:
- Keep business logic out of stored procedures.
- Be careful with engine-specific SQL features in hot paths.
- Use logical replication/CDC-friendly schemas (stable primary keys, append-only event tables when possible).
Bottom Line
Use PostgreSQL when your service will accumulate query complexity (joins, ad-hoc filters), when JSON is part of the product’s query surface, or when multi-tenant isolation needs first-class primitives like RLS. You’re signing up to operate vacuum and bloat consciously.
Use MySQL when your workload is predictable, your query patterns are stable, and you want the most common operational playbooks for replication and read scaling. JSON works best when you treat it as storage plus a small set of explicitly indexed generated columns.
If you’re still undecided after scoring: implement the JSON and concurrency patterns you expect to be painful, run them under load, and pick the engine whose failure mode you can live with.
PostgreSQL vs MySQL in 2026: a decision framework for new services is a choice you make once; operating it is a choice you make every week.
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.