PostgreSQL JSONB Performance Tuning in Production (2026)
Another “minor” schema choice. What broke this time?
I’ve watched teams ship JSONB because it felt faster than writing migrations, then spend the next quarter chasing p99 spikes, runaway GIN bloat, and query plans that change after an ANALYZE. They claim JSONB keeps you flexible. Sure. It also keeps your latency unpredictable unless you put guardrails around it.
Concerns first: the stuff the “happy path” doesn’t warn you about
JSONB fails in boring ways.
Your first incident rarely looks like “JSONB is slow.” It looks like autovacuum falling behind, WAL volume jumping, replicas lagging, and a perfectly reasonable query suddenly doing a Bitmap Heap Scan with a giant Recheck Cond. Why did it pick that plan today and not yesterday? Usually stats drift, skew, or an index that technically exists but does not narrow enough.
- GIN doesn’t just speed up reads: it also adds write amplification. If you update JSONB a lot, you pay in index maintenance and vacuum work.
- “Index exists” can still mean “reads half the table”: a Bitmap Index Scan followed by a fat Bitmap Heap Scan often means the index gets you close, then you recheck JSONB on a pile of heap pages anyway.
- Kubernetes kills long-running maintenance jobs: you start CREATE INDEX CONCURRENTLY, the Job hits a timeout or gets evicted, and you get to explain the half-finished migration to future you.
- Prepared statements can surprise you: some client patterns push the planner toward generic plans. Under tenant skew, a generic plan can go from “fine” to “how is this in production” fast.
If you cannot reproduce a JSONB performance fix on production-shaped data, you did not fix it. You got lucky.
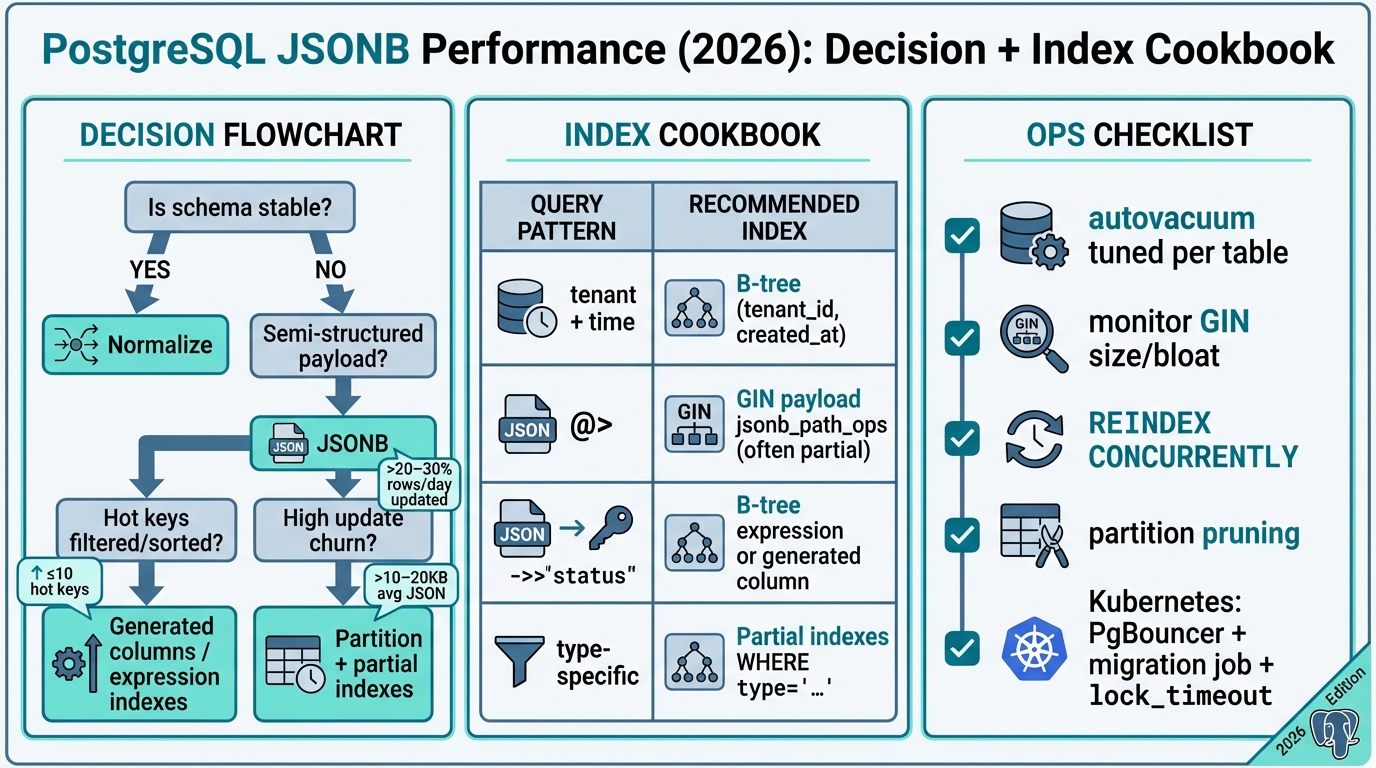
Decision guide: should this JSONB stay, or should you normalize?
Pick a side.
Engineers love “it depends,” but production loves clear trade-offs. Use JSONB when you know which keys you filter on and they do not change every sprint. Normalize when correctness depends on constraints, or when you keep discovering “one more key” you need to index.
- Use JSONB when filters stay stable: you filter on a small, known set of keys per endpoint, and you mostly do containment checks or point lookups.
- Normalize when you need relational rules: foreign keys, unique constraints, strict typing, and frequent joins across nested attributes want real columns.
- Normalize or go hybrid when churn stays high: if a large slice of your table updates JSONB daily, assume GIN churn and bloat unless you extract hot keys into columns.
- Move hot keys into columns when latency matters: if your top endpoint filters or sorts on JSON keys, do not bet your SLA on recheck-heavy GIN plans.
The thing nobody mentions is organizational, not technical. If you cannot get a migration reviewed in one day, teams will keep stuffing more “just one more field” into JSONB. Then you will index that JSONB. Then you will tune autovacuum. Then you will wonder why you did not add a column in the first place.
Diagnostics: read the plan like you’re trying to prove it wrong
Plans lie.
They lie politely, with tidy node names. Start with EXPLAIN (ANALYZE, BUFFERS) and treat every JSONB predicate as suspicious until you see stable buffers and a small heap read set. If you run the query ten times and the tenth run looks “fast,” you probably benchmarked cache, not your index.
- Start here every time: run EXPLAIN (ANALYZE, BUFFERS, VERBOSE) on the exact production query shape.
- Look for the recheck trap: Bitmap Heap Scan plus a big Recheck Cond often means “index helped, but not enough.”
- Narrow candidates before JSONB work: add tenant_id, created_at, and type predicates so Postgres can throw away 99% of rows before touching payload.
Some folks skip plan comparisons for patch releases and “simple” index changes. I don’t. I’ve seen a harmless stats change flip a plan from an Index Scan to a bitmap path that read 10x more heap blocks. I’ll believe “it’s safe” when I see buffers drop on production-shaped data.
Index strategy cookbook: boring B-trees first, then selective JSONB
Start boring.
Most JSONB tables behave like event tables. You filter by tenant, time window, maybe a type, then you check one or two JSON keys. So build the narrowing index first, even if it feels unrelated to JSONB.
- B-tree narrowing index (usually the first win): index (tenant_id, created_at) or (tenant_id, type, created_at) so JSONB checks run on a small candidate set.
- Expression indexes for hot scalar keys: if you filter on (payload->>’status’), index that expression with a B-tree. It often beats a generic GIN for equality filters.
- Partial indexes to keep GIN small: if only type=’purchase’ queries care about payment fields, index only those rows.
Now the controversial part. Teams treat GIN like a magic wand. I treat it like a power tool with no guard. Use GIN for containment where it pays off, not as a default tax on every write.
Choose the GIN operator class on purpose. If your workload mostly uses containment (@>), jsonb_path_ops often produces a smaller index than jsonb_ops. If you need broader operator support, keep jsonb_ops and accept the extra size and write cost. Test both on your data. Do not argue about it in Slack.
Generated columns: the “fine, we’re normalizing a little” compromise
This bit me once.
We had three services all querying payload->>’status’ with slightly different spellings, casts, and null handling. Half the queries missed the index. The fix looked boring: generated columns for the keys we actually used, plus a normal B-tree index. It felt like admitting defeat. It also made the incidents stop.
- Use generated columns for repeated hot keys: you reduce ORM mistakes and make index definitions readable.
- Accept the trade-off: you just created schema you must migrate. That’s still cheaper than rechecking large JSON blobs forever.
Partitioning: useful, but it won’t save a bad query
Partitioning helps until it hurts.
It shines when you drop old data, isolate noisy tenants, or keep GIN bloat contained to smaller physical structures. It disappoints when queries do not constrain the partition key, or when your client behavior stops pruning from working the way you expect. “We partitioned it” is not a performance strategy. It’s an operations strategy.
- Time range partitions: great for event/log tables and cheap retention. Index each partition with the minimum you need, not every index you can think of.
- Tenant hash partitions: good for strict multi-tenant isolation when one tenant keeps melting shared buffers.
- Pruning gotchas: wrapping created_at in functions, missing tenant/time predicates, and some prepared-statement patterns can reduce pruning. Test with your actual driver.
Ops: keeping GIN usable (autovacuum, bloat, rebuilds)
GIN bloat happens.
Unmanaged GIN bloat causes outages you will blame on “Postgres being slow.” If your JSONB updates touch a large share of rows, tune autovacuum per table and watch index growth. Defaults often lag behind high-churn workloads, and vacuum does not sprint because you asked nicely.
- Tune autovacuum per table: lower scale factors on high-churn JSONB tables so stats and visibility maps do not drift.
- Watch index size vs table size: if GIN grows faster than the table and vacuum cannot keep up, switch to partial GIN, extract hot keys, or partition to contain churn.
- Rebuild safely: use CREATE INDEX CONCURRENTLY and set lock_timeout so you fail fast instead of waiting forever on locks.
Ignore the GitHub commit count. It’s a vanity metric. Watch heap blocks, WAL volume, and vacuum lag.
App and Kubernetes patterns: ORMs and rollouts cause half the pain
Your ORM does not care about your indexes.
I’ve seen Prisma and TypeORM generate JSON predicates that look “right” in the app code but do not map cleanly to indexable Postgres operators. For hot paths, write SQL that you can explain, test, and keep stable. Yes, raw SQL. Do not pretend you will “optimize later” and then act surprised when later arrives.
- Keep containment queries explicit: use payload @> $1::jsonb for GIN-friendly containment.
- Keep scalar filters indexable: use payload->>’key’ = ‘value’ when you have an expression or generated-column index.
- Run index builds outside app startup: use a dedicated migration Job, set timeouts, and make sure the Job will not get killed mid-build.
Other stuff in this release: dependency bumps, some image updates, the usual. And then the one change that takes your database down. Anyway.
Grudging recommendation
I’d wait a week.
If you already run JSONB at scale and you feel “fine,” do not touch anything on a Friday because you read an indexing tip. Capture current plans for your top queries, test a single change in staging with production-shaped skew, then ship: B-tree narrowing first, expression or generated columns for hot keys, and selective GIN (often partial) for containment. If churn stays high, plan a hybrid schema. You can keep the JSONB. Just stop pretending it’s free.
🛠️ Try These Free Tools
Paste your Kubernetes YAML to detect deprecated APIs before upgrading.
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.