PostgreSQL 18 logical replication: tuning and zero-downtime cutover checklist
ReleaseRun published an operator runbook on 2026-05-08 for PostgreSQL 18 logical replication, focused on tuning WAL throughput, slot safety, and near-zero-downtime cutovers.
TL;DR
In short: Upgrade your process, not just your version. Use this if you run PostgreSQL logical replication for a major upgrade or migration and you cannot afford a surprise pg_wal fill-up during the cutover window.
Key changes (what this runbook emphasizes)
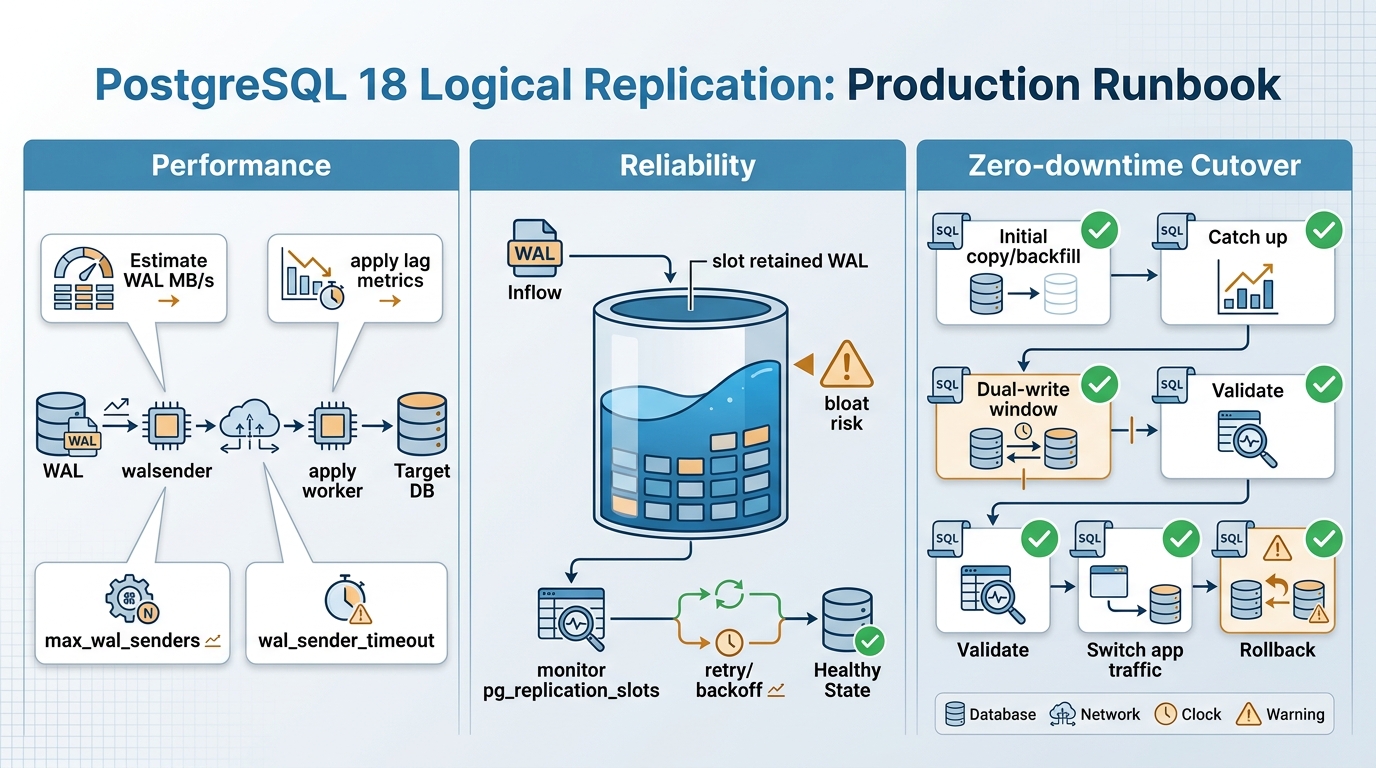
- Size for apply load, not read load: The runbook tells operators to treat the subscriber like a write-heavy system with index maintenance, triggers, foreign keys, and autovacuum overhead.
- Put replication slots on a budget: It frames slot-retained WAL as a disk-outage risk and provides a query to track retained WAL per logical slot.
- Measure lag two ways: It pairs byte lag (LSN distance) with time lag (commit freshness) using pg_stat_replication and pg_stat_subscription queries.
- Cutover is a controlled write event: The cutover plan centers on write-freeze plus validation queries, not a single “flip the connection string” step.
- Copy and paste preflight SQL: It includes a publisher and subscriber checklist for senders, slots, replication status, and replica identity red flags.
Details
The guide describes logical replication as table-level change streaming. A publisher sends changes defined by a publication, and a subscriber consumes them via a subscription.
Slots matter. A replication slot keeps WAL on the publisher until the subscriber confirms receipt, so a slow or down subscriber can turn into a disk-pressure incident.
Production topology terms (publisher, subscriber, slot)
- Publication (publisher): Defines which tables replicate. Tables outside the publication do not replicate.
- Subscription (subscriber): Holds the connection details and apply behavior, including whether to do an initial copy.
- Replication slot (publisher): Retains WAL until the subscriber advances. The runbook calls this “backpressure” and a risk if you ignore it.
- walsender (publisher): A per-subscription sender process capped by max_wal_senders.
- Apply workers (subscriber): Replay changes and can bottleneck on CPU, indexes, triggers, and commit rate.
Sizing and performance: estimate WAL before you size anything
The runbook’s sizing advice starts with WAL volume, measured during a peak window. It suggests translating WAL MB/s into network throughput, storage IOPS, and a slot-retention budget.
Start with measurement. Take two samples 60 seconds apart using pg_current_wal_lsn, then compute the delta.
- Network sizing: Provision sustained throughput at or above peak WAL MB/s, plus headroom for retransmits and initial sync.
- Subscriber sizing: Plan for write amplification. Apply can hit random I/O patterns on the subscriber due to index layout and trigger work.
- Slot retention math: Use wal_mb_per_sec multiplied by worst_case_outage_seconds to estimate how much WAL the publisher might retain if the subscriber stops advancing.
Tuning knobs that cap throughput
The runbook focuses on removing accidental ceilings. It highlights max_wal_senders and max_replication_slots on the publisher, and worker ceilings on the subscriber.
- Publisher ceilings: Set max_wal_senders at or above your subscription count with headroom, and set max_replication_slots for expected logical slots plus margin.
- Subscriber worker ceilings: Ensure max_worker_processes and max_logical_replication_workers can run apply plus any initial table sync workers.
- Apply cost controls: Every index and trigger executes on the subscriber during apply. The runbook suggests temporarily reducing this work when you need catch-up speed.
Lag measurement (LSN and time)
The guide recommends tracking lag using pg_stat_replication on the publisher and pg_stat_subscription on the subscriber. It calls out byte lag and commit time freshness as separate signals.
- Alert trend, not spikes: It recommends alerting on increasing byte lag over a fixed window, rather than paging on a single burst.
- Slot stuck detection: It advises alerting if restart_lsn stops advancing while WAL generation continues.
- Flapping detection: It flags connecting and streaming status flips as a sign of network or authentication churn.
Reliability and conflict handling
The runbook puts slot monitoring at the center of reliability. It provides a pg_replication_slots query that computes retained WAL using pg_wal_lsn_diff against pg_current_wal_lsn.
This is the part that usually hurts. A forgotten logical slot can fill disks while the application looks healthy.
- Set a retained-WAL budget: Define a hard cap in GB based on disk headroom and your longest acceptable subscriber outage.
- Pick a policy for unrecoverable lag: It lists three strategies: allocate enough disk, kill and rebuild the subscription, or reduce publisher write volume during subscriber downtime.
- Do not drop slots casually: The runbook warns that dropping a slot stops WAL retention but implies subscriber data loss and a full re-seed.
Conflicts: logical replication is not multi-master
According to the runbook, native logical replication does not provide automatic multi-writer conflict resolution. It recommends enforcing ownership rules so conflicts cannot happen.
- Single writer per table: Route writes so only one cluster updates replicated tables. This trades application routing complexity for operational calm.
- Single writer per tenant or key range: Partition ownership so each side writes disjoint keys, then accept the cost of rebalancing.
- Append-only models: Prefer insert-only event logs with dedupe in the reader when you need simpler operations.
- Dual-write at the app: Use deterministic IDs and idempotent semantics if you cannot freeze writes. The runbook describes this as harder than it sounds.
Zero-downtime cutover runbook (with rollback)
The guide’s cutover assumes “old” as publisher and “new” as subscriber. It describes the hardest part as write control during the final switch.
So. Write-freeze wins most of the time, unless you already built dual-write and reconciliation.
Phase 0: prerequisites
- Schema parity: Logical replication does not replicate DDL, so operators must create tables, types, sequences, functions, and extensions on the subscriber before the cutover.
- Permissions: Create a replication user on the publisher with REPLICATION privilege and grant access to published tables.
- Replica identity: Ensure every replicated table has a stable identity, typically a primary key, to support UPDATE and DELETE.
- WAL headroom: Size publisher disk for worst-case slot retention during the migration window.
Phase 1 and 2: publication and subscription
The runbook describes two subscription approaches. Use built-in initial copy for simplicity, or restore a snapshot and set copy_data = false for large datasets.
- Publication scope: It notes that FOR ALL TABLES increases blast radius, because new tables later start replicating automatically.
- External backfill: The guide recommends snapshot or backup restore for large databases, then starts replication without the built-in copy.
Phase 3 to 6: catch-up, validate, cut over
The guide recommends operating until lag stays small and stable under real traffic. It then proposes either a write-freeze cutover or a dual-write window.
- Validation before switching: It suggests row counts, checksums over stable slices, and “high-water mark” queries like max(id) or max(updated_at).
- Cutover action: Enable write-freeze on the old system, wait for 0 lag, run validation, then switch application traffic to the new system.
- Soak and cleanup: Keep replication running briefly to catch accidental old writes, then disable the subscription and remove publication and slot.
Rollback (what the guide warns about)
The team describes rollback as “not flip back.” If you accept writes on the new system, switching back to the old system drops those writes unless you engineered reverse replication or dual-write reconciliation.
Other stuff in this release: dependency bumps, some image updates, the usual.
Background
Logical replication often shows up in major upgrades, migrations between regions, and “split the monolith database” projects because it keeps two clusters in sync at the table level.
The runbook points readers to official PostgreSQL documentation for logical replication, replication slots, and PostgreSQL 18 release notes for version-specific changes.
🛠️ Try These Free Tools
Paste your dependency file to check for end-of-life packages.
Plan your upgrade path with breaking change warnings and step-by-step guidance.
Check extension compatibility across PostgreSQL versions.